
Last week, Microsoft announced the final release of Windows Server 2016 (the bits can be downloaded here). In addition, Microsoft has announced that Windows Server 2016 supports now a 2-node hyperconverged cluster configuration. I can now publish the setup of my lab configuration which is almost a production platform. Only SSD are not enterprise grade and one Xeon is missing per server. But to show you how it is easy to implement a hyperconverged solution it is fine. In this topic, I will show you how to deploy a 2-node hyperconverged cluster from the beginning with Windows Server 2016. But before running some PowerShell cmdlet, let’s take a look on the design.
Design overview
In this part I’ll talk about the implemented hardware and how are connected both nodes. Then I’ll introduce the network design and the required software implementation.

Hardware consideration
First of all, it is necessary to present you the design. I have bought two nodes that I have built myself. Both nodes are not provided by a manufacturer. Below you can find the hardware that I have implemented in each node:
- CPU: Xeon 2620v2
- Motherboard: Asus Z9PA-U8 with ASMB6-iKVM for KVM-over-Internet (Baseboard Management Controller)
- PSU: Fortron 350W FSP FSP350-60GHC
- Case: Dexlan 4U IPC-E450
- RAM: 128GB DDR3 registered ECC
-
Storage devices:
- 1x Intel SSD 530 128GB for the Operating System
- 1x Samsung NVMe SSD 950 Pro 256GB (Storage Spaces Direct cache)
- 4x Samsung SATA SSD 850 EVO 500GB (Storage Spaces Direct capacity)
-
Network Adapters:
- 1x Intel 82574L 1GB for VM workloads (two controllers). Integrated to motherboard
- 1x Mellanox Connectx3-Pro 10GB for storage and live-migration workloads (two controllers). Mellanox are connected with two passive copper cables with SFP provided by Mellanox
- 1x Switch Ubiquiti ES-24-Lite 1GB
If I were in production, I’d replace SSD by enterprise grade SSD and I’d add a NVMe SSD for the caching. To finish I’d buy server with two Xeon. Below you can find the hardware implementation.

Network design
To support this configuration, I have created five network subnets:
- Management network: 10.10.0.0/24 – VID 10 (Native VLAN). This network is used for Active Directory, management through RDS or PowerShell and so on. Fabric VMs will be also connected to this subnet.
- DMZ network: 10.10.10.0/24 – VID 11. This network is used by DMZ VMs as web servers, AD FS etc.
- Cluster network: 10.10.100/24 – VID 100. This is the cluster heart beating network
- Storage01 network: 10.10.101/24 – VID 101. This is the first storage network. It is used for SMB 3.11 transaction and for Live-Migration.
- Storage02 network: 10.10.102/24 – VID 102. This is the second storage network. It is used for SMB 3.11 transaction and for Live-Migration.
I can’t leverage Simplified SMB MultiChannel because I don’t have a 10GB switch. So each 10GB controller must belong to separate subnets.
I will deploy a Switch Embedded Teaming for 1GB network adapters. I will not implement a Switch Embedded Teaming for 10GB because a switch is missing.
Logical design
I will have two nodes called pyhyv01 and pyhyv02 (Physical Hyper-V).
The first challenge concerns the failover cluster. Because I have no other physical server, the domain controllers will be virtual. if I implement domain controllers VM in the cluster, how can start the cluster? So the DC VMs must not be in the cluster and must be stored locally. To support high availability, both nodes will host a domain controller locally in the system volume (C:\). In this way, the node boot, the DC VM start and then the failover cluster can start.
Both nodes are deployed in core mode because I really don’t like graphical user interface for hypervisors. I don’t deploy the Nano Server because I don’t like the Current Branch for Business model for Hyper-V and storage usage. The following feature will be deployed for both nodes:
- Hyper-V + PowerShell management tools
- Failover Cluster + PowerShell management tools
- Storage Replica (this is optional, only if you need the storage replica feature)

The storage configuration will be easy: I’ll create a unique Storage Pool with all SATA and NVMe SSD. Then I will create two Cluster Shared Volumes that will be distributed across both nodes. The CSV will be called CSV-01 and CSV-02.
Operating system configuration
I show how to configure a single node. You have to repeat these operations for the second node in the same way. This is why I recommend you to make a script with the commands: the script will help to avoid human errors.
Bios configuration
The bios may change regarding the manufacturer and the motherboard. But I always do the same things in each server:
- Check if the server boot in UEFI
- Enable virtualization technologies as VT-d, VT-x, SLAT and so on
- Configure the server in high performance (in order that CPUs have the maximum frequency available)
- Enable HyperThreading
- Disable all unwanted hardware (audio card, serial/com port and so on)
- Disable PXE boot on unwanted network adapters to speed up the boot of the server
- Set the date/time
Next I check if the memory is seen, and all storage devices are plugged. When I have time, I run a memtest on server to validate hardware.
OS first settings
I have deployed my nodes from a USB stick configured with Easy2Boot. Once the system is installed, I have deployed drivers for motherboard and for Mellanox network adapters. Because I can’t connect with a remote MMC to Device Manager, I use the following commands to list if drivers are installed:
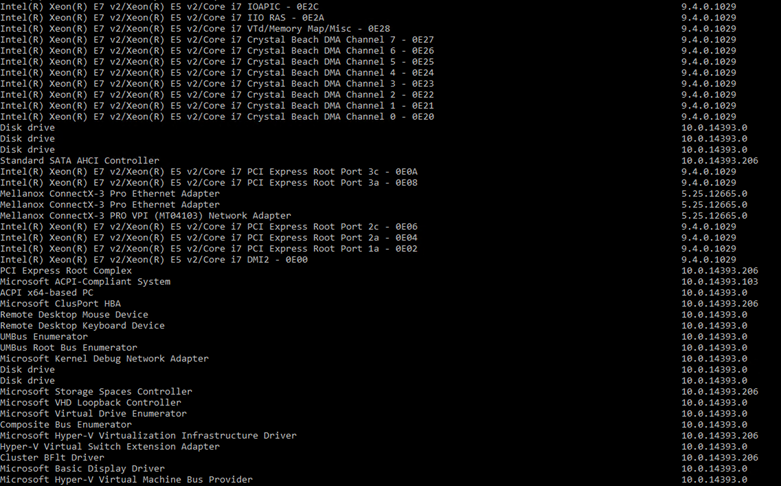
gwmi Win32_SystemDriver | select name,@{n="version";e={(gi $_.pathname).VersionInfo.FileVersion}}
gwmi Win32_PnPSignedDriver | select devicename,driverversion
After all drivers are installed, I configure the server name, the updates, the remote connection and so on. For this, I use sconfig.
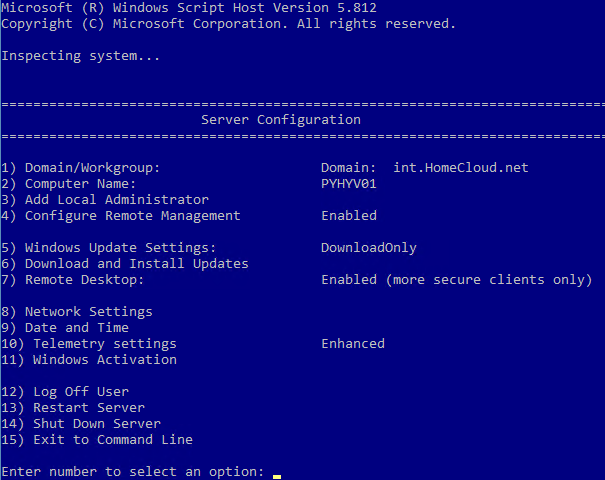
This tool is easy, but don’t provide automation. You can do the same thing with PowerShell cmdlet, but I have only two nodes to deploy and I find this easier. All you have to do, is to move in menu and set parameters. Here I have changed the computer name, I have enabled the remote desktop and I have downloaded and installed all updates. I heavily recommend you to install all updates before deploying the Storage Spaces Direct.
Then I configure the power options to “performance” by using the bellow cmdlet:
POWERCFG.EXE /S SCHEME_MIN
Once the configuration is finished, you can install the required roles and features. You can run the following cmdlet on both nodes:
Install-WindowsFeature Hyper-V, Data-Center-Bridging, Failover-Clustering, RSAT-Clustering-Powershell, Hyper-V-PowerShell, Storage-Replica
Once you have run this cmdlet the following roles and features are deployed:
- Hyper-V + PowerShell module
- Datacenter Bridging
- Failover Clustering + PowerShell module
- Storage Replica
Network settings
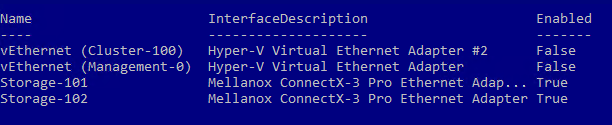
Once the OS configuration is finished, you can configure the network. First, I rename network adapters as below:
get-netadapter |? Name -notlike vEthernet* |? InterfaceDescription -like Mellanox*#2 | Rename-NetAdapter -NewName Storage-101 get-netadapter |? Name -notlike vEthernet* |? InterfaceDescription -like Mellanox*Adapter | Rename-NetAdapter -NewName Storage-102 get-netadapter |? Name -notlike vEthernet* |? InterfaceDescription -like Intel*#2 | Rename-NetAdapter -NewName Management01-0 get-netadapter |? Name -notlike vEthernet* |? InterfaceDescription -like Intel*Connection | Rename-NetAdapter -NewName Management02-0

Next I create the Switch Embedded Teaming with both 1GB network adapters called SW-1G:
New-VMSwitch -Name SW-1G -NetAdapterName Management01-0, Management02-0 -EnableEmbeddedTeaming $True -AllowManagementOS $False
Now we can create two virtual network adapters for the management and the heartbeat:
Add-VMNetworkAdapter -SwitchName SW-1G -ManagementOS -Name Management-0 Add-VMNetworkAdapter -SwitchName SW-1G -ManagementOS -Name Cluster-100

Then I configure VLAN on vNIC and on storage NIC:
Set-VMNetworkAdapterVLAN -ManagementOS -VMNetworkAdapterName Cluster-100 -Access -VlanId 100 Set-NetAdapter -Name Storage-101 -VlanID 101 -Confirm:$False Set-NetAdapter -Name Storage-102 -VlanID 102 -Confirm:$False
Below screenshot shows the VLAN configuration on physical and virtual adapters.


Next I disable VM queue (VMQ) on 1GB network adapters and I set it on 10GB network adapters. When I set the VMQ, I use multiple of 2 because hyperthreading is enabled. I start with a base processor number of 2 because it is recommended to leave the first core (core 0) for other processes.
Disable-NetAdapterVMQ -Name Management* # Core 1, 2 & 3 will be used for network traffic on Storage-101 Set-NetAdapterRSS Storage-101 -BaseProcessorNumber 2 -MaxProcessors 2 -MaxProcessorNumber 4 #Core 4 & 5 will be used for network traffic on Storage-102 Set-NetAdapterRSS Storage-102 -BaseProcessorNumber 6 -MaxProcessors 2 -MaxProcessorNumber 8
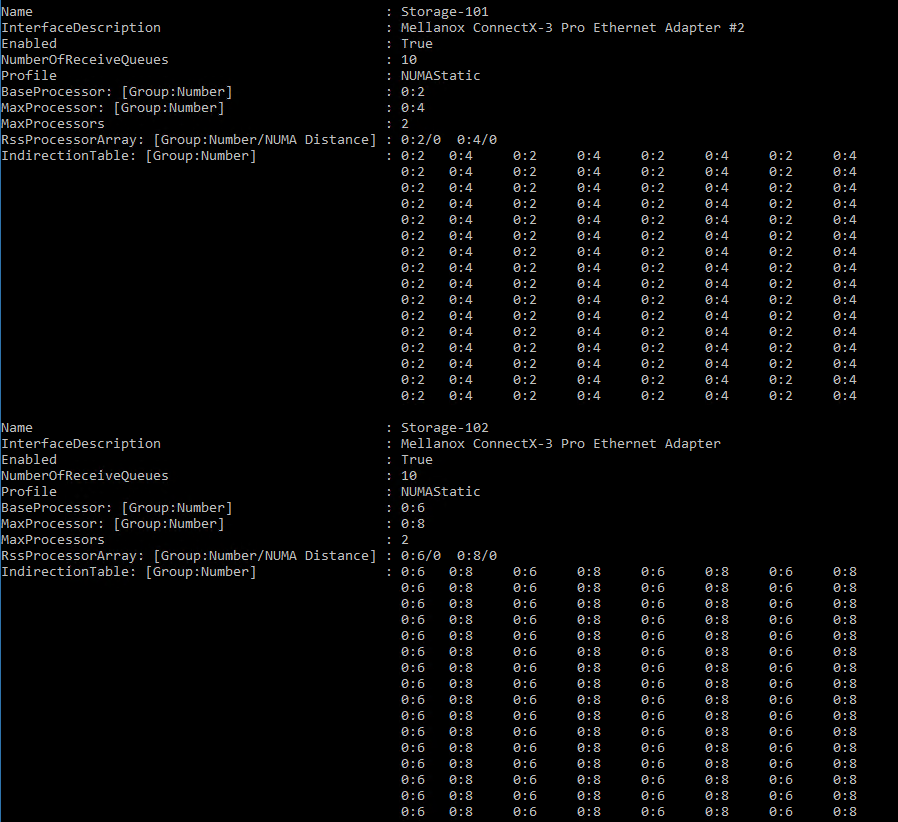
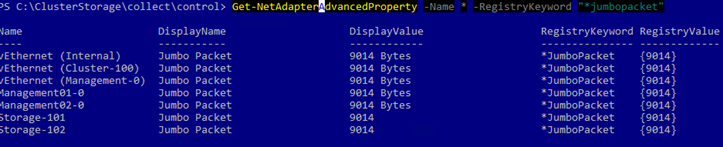
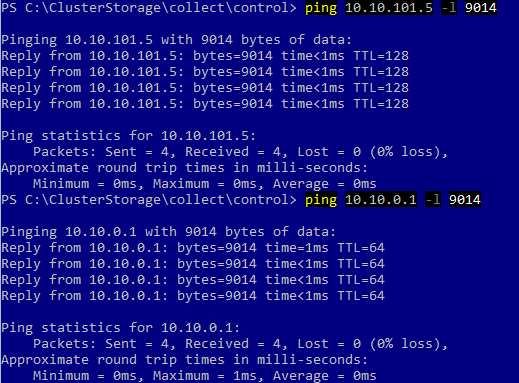
Next I configure Jumbo Frame on each network adapter.
Get-NetAdapterAdvancedProperty -Name * -RegistryKeyword "*jumbopacket" | Set-NetAdapterAdvancedProperty -RegistryValue 9014
Now we can enable RDMA on storage NICs:
Get-NetAdapter *Storage* | Enable-NetAdapterRDMA
The below screenshot is the result of Get-NetAdapterRDMA.
Even if it is useless because I have no switch and other connections on 10GB network adapters, I configure DCB:
# Turn on DCB Install-WindowsFeature Data-Center-Bridging # Set a policy for SMB-Direct New-NetQosPolicy "SMB" -NetDirectPortMatchCondition 445 -PriorityValue8021Action 3 # Turn on Flow Control for SMB Enable-NetQosFlowControl -Priority 3 # Make sure flow control is off for other traffic Disable-NetQosFlowControl -Priority 0,1,2,4,5,6,7 # Apply policy to the target adapters Enable-NetAdapterQos -InterfaceAlias "Storage-101" Enable-NetAdapterQos -InterfaceAlias "Storage-102" # Give SMB Direct 30% of the bandwidth minimum New-NetQosTrafficClass "SMB" -Priority 3 -BandwidthPercentage 30 -Algorithm ETS
Ok, now that network adapters are configured, we can configure IP addresses and try the communication on the network.
New-NetIPAddress -InterfaceAlias "vEthernet (Management-0)" -IPAddress 10.10.0.5 -PrefixLength 24 -DefaultGateway 10.10.0.1 -Type Unicast | Out-Null Set-DnsClientServerAddress -InterfaceAlias "vEthernet (Management-0)" -ServerAddresses 10.10.0.20 | Out-Null New-NetIPAddress -InterfaceAlias "vEthernet (Cluster-100)" -IPAddress 10.10.100.5 -PrefixLength 24 -Type Unicast | Out-Null New-NetIPAddress -InterfaceAlias "Storage-101" -IPAddress 10.10.101.5 -PrefixLength 24 -Type Unicast | Out-Null New-NetIPAddress -InterfaceAlias "Storage-102" -IPAddress 10.10.102.5 -PrefixLength 24 -Type Unicast | Out-Null #Disable DNS registration of Storage and Cluster network adapter (Thanks to Philip Elder :)) Set-DNSClient -InterfaceAlias Storage* -RegisterThisConnectionsAddress $False Set-DNSClient -InterfaceAlias *Cluster* -RegisterThisConnectionsAddress $False

Then I try the Jumbo Frame: it is working.
Now my nodes can communicate with other friends through the network. Once you have reproduced these steps on the second node, we can deploy the domain controller.
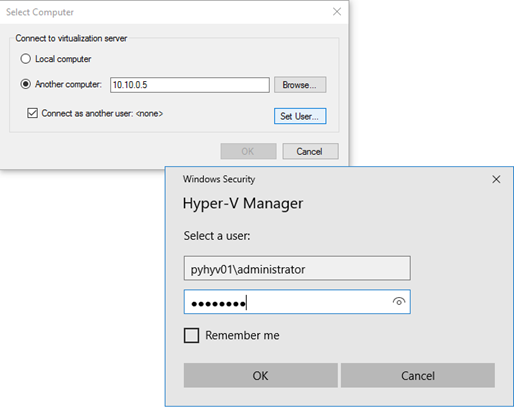
Connect to Hyper-V remotely
To make future actions, I work from my laptop with remote PowerShell. To display the Hyper-V VM consoles, I have installed RSAT on my Windows 10. Then I have installed the Hyper-V console:
Before being able to connect to Hyper-V remotely, some configurations are required from the server and client perspectives. In both nodes, run the following cmdlets:
Enable-WSManCredSSP -Role server
In your laptop, run the following cmdlets (replace fqdn-of-hyper-v-host by the future Hyper-V hosts FQDN):
Set-Item WSMan:\localhost\Client\TrustedHosts -Value "10.10.0.5" Set-Item WSMan:\localhost\Client\TrustedHosts -Value "fqdn-of-hyper-v-host" Set-Item WSMan:\localhost\Client\TrustedHosts -Value "10.10.0.6" Set-Item WSMan:\localhost\Client\TrustedHosts -Value "fqdn-of-hyper-v-host" Enable-WSManCredSSP -Role client -DelegateComputer "10.10.0.5" Enable-WSManCredSSP -Role client -DelegateComputer "fqdn-of-hyper-v-host" Enable-WSManCredSSP -Role client -DelegateComputer "10.10.0.6" Enable-WSManCredSSP -Role client -DelegateComputer "fqdn-of-hyper-v-host"
Then, run gpedit.msc and configure the following policy:
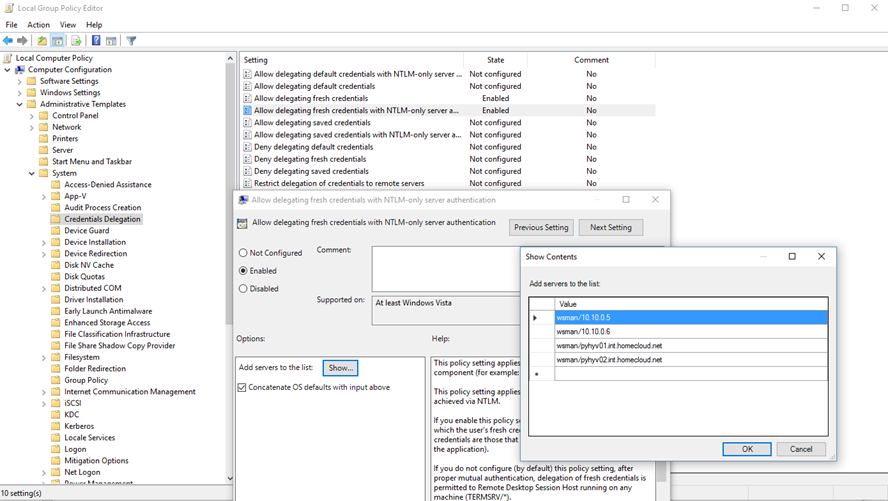
Now you can leverage the new Hyper-V manager capability which enable to use an alternative credential to connect to Hyper-V.
Domain controller deployment
Before deploying the VM, I have copied the Windows Server 2016 ISO in c:\temp of both nodes. Then I have run the following script from my laptop:
# Create the first DC VM Enter-PSSession -ComputerName 10.10.0.5 -Credential pyhyv01\administrator $VMName = "VMADS01" # Create Gen 2 VM with dynamic memory, autostart action to 0s and auto stop action set. 2vCPU New-VM -Generation 2 -Name $VMName -SwitchName SW-1G -NoVHD -MemoryStartupBytes 2048MB -Path C:\VirtualMachines Set-VM -Name $VMName -ProcessorCount 2 -DynamicMemory -MemoryMinimumBytes 1024MB -MemoryMaximumBytes 4096MB -MemoryStartupBytes 2048MB -AutomaticStartAction Start -AutomaticStopAction ShutDown -AutomaticStartDelay 0 -AutomaticCriticalErrorAction None -CheckpointType Production # Create and add a 60GB dynamic VHDX to the VM New-VHD -Path C:\VirtualMachines\$VMName\W2016-STD-1.0.vhdx -SizeBytes 60GB -Dynamic Add-VMHardDiskDrive -VMName $VMName -Path C:\VirtualMachines\$VMName\W2016-STD-1.0.vhdx # Rename the network adapter Get-VMNetworkAdapter -VMName $VMName | Rename-VMNetworkAdapter -NewName Management-0 # Add a DVD drive with W2016 ISO Add-VMDvdDrive -VMName $VMName Set-VMDvdDrive -VMName $VMName -Path C:\temp\14393.0.160715-1616.RS1_RELEASE_SERVER_EVAL_X64FRE_EN-US.ISO # Set the DVD drive as first boot $VD = Get-VMHardDiskDrive -VMName $VMName -ControllerNumber 0 -ControllerLocation 1 Set-VMFirmware -VMName $VMName -FirstBootDevice $VD # Add a data disk to the VM (10GB dynamic) New-VHD -Path C:\VirtualMachines\$VMName\data.vhdx -SizeBytes 10GB -Dynamic Add-VMHardDiskDrive -VMName $VMName -Path C:\VirtualMachines\$VMName\Data.vhdx # Start the VM Start-VM Exit # Create the second DC VM with the same capabilities as below Enter-PSSession -ComputerName 10.10.0.6 -Credential pyhyv02\administrator $VMName = "VMADS02" New-VM -Generation 2 -Name $VMName -SwitchName SW-1G -NoVHD -MemoryStartupBytes 2048MB -Path C:\VirtualMachines Set-VM -Name $VMName -ProcessorCount 2 -DynamicMemory -MemoryMinimumBytes 1024MB -MemoryMaximumBytes 4096MB -MemoryStartupBytes 2048MB -AutomaticStartAction Start -AutomaticStopAction ShutDown -AutomaticStartDelay 0 -AutomaticCriticalErrorAction None -CheckpointType Production New-VHD -Path C:\VirtualMachines\$VMName\W2016-STD-1.0.vhdx -SizeBytes 60GB -Dynamic Add-VMHardDiskDrive -VMName $VMName -Path C:\VirtualMachines\$VMName\W2016-STD-1.0.vhdx Get-VMNetworkAdapter -VMName $VMName | Rename-VMNetworkAdapter -NewName Management-0 Add-VMDvdDrive -VMName $VMName Set-VMDvdDrive -VMName $VMName -Path C:\temp\14393.0.160715-1616.RS1_RELEASE_SERVER_EVAL_X64FRE_EN-US.ISO $VD = Get-VMHardDiskDrive -VMName $VMName -ControllerNumber 0 -ControllerLocation 1 Set-VMFirmware -VMName $VMName -FirstBootDevice $VD New-VHD -Path C:\VirtualMachines\$VMName\data.vhdx -SizeBytes 10GB -Dynamic Add-VMHardDiskDrive -VMName $VMName -Path C:\VirtualMachines\$VMName\Data.vhdx Start-VM Exit
Deploy the first domain controller
Once the VMs are created, you can connect to their consoles from Hyper-V manager to install the OS. A better way is to use a sysprep’d image. But because it is a “from scratch” infrastructure, I don’t have a gold master. By using sconfig, you can install updates and enable Remote Desktop. Once the operating systems are deployed, you can connect to the VM across PowerShell Direct.
Below you can find the configuration of the first domain controller:
# Remote connection to first node
Enter-PSSession -ComputerName 10.10.0.5 -Credential pyhyv01\administrator
# Establish a PowerShell direct session to VMADS01
Enter-PSSession -VMName VMADS01 -Credential VMADS01\administrator
# Rename network adapter
Rename-NetAdapter -Name Ethernet -NewName Management-0
# Set IP Addresses
New-NetIPAddress -InterfaceAlias "Management-0" -IPAddress 10.10.0.20 -PrefixLength 24 -Type Unicast | Out-Null
# Set the DNS (this IP is my DNS server for internet in my lab)
Set-DnsClientServerAddress -InterfaceAlias "Management-0" -ServerAddresses 10.10.0.229 | Out-Null
# Initialize and mount the data disk
initialize-disk -Number 1
New-Volume -DiskNumber 1 -FileSystem NTFS -FriendlyName Data -DriveLetter E
# Install required feature
install-WindowsFeature AD-Domain-Services, DNS -IncludeManagementTools
# Deploy the forest
Import-Module ADDSDeployment
Install-ADDSForest `
-CreateDnsDelegation:$false `
-DatabasePath "E:\NTDS" `
-DomainMode "WinThreshold" ` #should be soon Win2016
-DomainName "int.HomeCloud.net" `
-DomainNetbiosName "INTHOMECLOUD" `
-ForestMode "WinThreshold" ` #should be soon Win2016
-InstallDns:$true `
-LogPath "E:\NTDS" `
-NoRebootOnCompletion:$false `
-SysvolPath "E:\SYSVOL" `
-Force:$true
Promote the second domain controller
Once the first domain controller is deployed and the forest is ready, you can promote the second domain controller:
Enter-PSSession -ComputerName 10.10.0.6 -Credential pyhyv02\administrator
# Establish a PowerShell direct session to VMADS02
Enter-PSSession -VMName VMADS02 -Credential VMADS02\administrator
# Rename network adapter
Rename-NetAdapter -Name Ethernet -NewName Management-0
# Set IP Addresses
New-NetIPAddress -InterfaceAlias "Management-0" -IPAddress 10.10.0.21 -PrefixLength 24 -Type Unicast | Out-Null
# Set the DNS to the first DC
Set-DnsClientServerAddress -InterfaceAlias "Management-0" -ServerAddresses 10.10.0.20 | Out-Null
# Initialize and mount the data disk
initialize-disk -Number 1
New-Volume -DiskNumber 1 -FileSystem NTFS -FriendlyName Data -DriveLetter E
# Install required feature
install-WindowsFeature AD-Domain-Services, DNS -IncludeManagementTools
# Deploy the forest
Import-Module ADDSDeployment
Install-ADDSDomainController `
-NoGlobalCatalog:$false `
-CreateDnsDelegation:$false `
-Credential (Get-Credential) `
-CriticalReplicationOnly:$false `
-DatabasePath "E:\NTDS" `
-DomainName "int.HomeCloud.net" `
-InstallDns:$true `
-LogPath "E:\NTDS" `
-NoRebootOnCompletion:$false `
-SiteName "Default-First-Site-Name" `
-SysvolPath "E:\SYSVOL" `
-Force:$true
Configure the directory
Once the second server has rebooted, we can configure the directory has below:
Enter-PSSession -computername VMADS01.int.homecloud.net #Requires -version 4.0 $DN = "DC=int,DC=HomeCloud,DC=net" # New Default OU New-ADOrganizationalUnit -Name "Default" -Path $DN $DefaultDN = "OU=Default,$DN" New-ADOrganizationalUnit -Name "Computers" -Path $DefaultDN New-ADOrganizationalUnit -Name "Users" -Path $DefaultDN # Redir container to OU cmd /c redircmp "OU=Computers,OU=Default,$DN" cmd /c redirusr "OU=Users,OU=Default,$DN" # Create Accounts tree New-ADOrganizationalUnit -Name "Accounts" -Path $DN $AccountOU = "OU=Accounts,$DN" New-ADOrganizationalUnit -Name "Users" -Path $AccountOU New-ADOrganizationalUnit -Name "Groups" -Path $AccountOU New-ADOrganizationalUnit -Name "Services" -Path $AccountOU # Create Servers tree New-ADOrganizationalUnit -Name "Servers" -Path $DN $ServersOU = "OU=Servers,$DN" New-ADOrganizationalUnit -Name "Computers" -Path $ServersOU New-ADOrganizationalUnit -Name "Groups" -Path $ServersOU New-ADOrganizationalUnit -Name "CNO" -Path $ServersOU # New User's groups $GroupAcctOU = "OU=Groups,$AccountOU" New-ADGroup -Name "GG-FabricAdmins" -Path $GroupAcctOU -GroupScope DomainLocal -Description "Fabric Server's administrators" New-ADGroup -Name "GG-SQLAdmins" -Path $GroupAcctOU -GroupScope DomainLocal -Description "SQL Database's administrators" # New Computer's groups $GroupCMPOU = "OU=Groups,$ServersOU" New-ADGroup -Name "GG-Hyperv" -Path $GroupCMPOU -GroupScope DomainLocal -Description "Hyper-V Servers" New-ADGroup -Name "GG-FabricServers" -Path $GroupCMPOU -GroupScope DomainLocal -Description "Fabric servers" New-ADGroup -Name "GG-SQLServers" -Path $GroupCMPOU -GroupScope DomainLocal -Description "SQL Servers" Exit
Ok, our Active Directory is ready, we can now add Hyper-V nodes to the domain 🙂
Add nodes to domain
To add both nodes to the domain, I run the following cmdlets from my laptop:
Enter-PSSession -ComputerName 10.10.0.5 -Credential pyhyv01\administrator $domain = "int.homecloud.net" $password = "P@$$w0rd" | ConvertTo-SecureString -asPlainText -Force $username = "$domain\administrator" $credential = New-Object System.Management.Automation.PSCredential($username,$password) Add-Computer -DomainName $domain -Credential $credential -OUPath "OU=Computers,OU=Servers,DC=int,DC=HomeCloud,DC=net" -Restart
Wait that pyhyv01 has rebooted and run the following cmdlet on pyhyv02. Now you can log on on pyhyv01 and pyhyv02 with domain credential. You can install Domain Services RSAT on the laptop to parse the Active Directory.
2-node hyperconverged cluster deployment
Now that the Active Directory is available, we can deploy the cluster. First, I test the cluster to verify that all is ok:
Enter-PSSession -ComputerName pyhyv01.int.homecloud.net -credential inthomecloud\administrator Test-Cluster pyhyv01, pyhyv02 -Include "Storage Spaces Direct",Inventory,Network,"System Configuration"
Check the report if they are issues with the configuration. If the report is good, run the following cmdlets:
# Create the cluster New-Cluster -Name Cluster-Hyv01 -Node pyhyv01,pyhyv02 -NoStorage -StaticAddress 10.10.0.10
Once the cluster is created, I set a Cloud Witness in order that Azure has a vote for the quorum.
# Add a cloud Witness (require Microsoft Azure account) Set-ClusterQuorum -CloudWitness -Cluster Cluster-Hyv01 -AccountName "<StorageAccount>" -AccessKey "<AccessKey>"
Then I configure the network name in the cluster:
#Configure network name (Get-ClusterNetwork -Name "Cluster Network 1").Name="Storage-102" (Get-ClusterNetwork -Name "Cluster Network 2").Name="Storage-101" (Get-ClusterNetwork -Name "Cluster Network 3").Name="Cluster-100" (Get-ClusterNetwork -Name "Cluster Network 4").Name="Management-0"
Next I configure the Node Fairness to run each time a node is added to the cluster and every 30mn. When the CPU of a node will be utilized at 70%, the node fairness will balance the VM across other nodes.
# Configure Node Fairness (Get-Cluster).AutoBalancerMode = 2 (Get-Cluster).AutoBalancerLevel = 2
Then I configure the Fault Domain Awareness to have a fault tolerance based on rack. It is useless in this configuration, but if you add nodes to the cluster, it can be useful. I enable this because it is recommended to make this configuration before enabling Storage Spaces Direct.
# Configure the Fault Domain Awareness New-ClusterFaultDomain -Type Site -Name "Lyon" New-ClusterFaultDomain -Type Rack -Name "Rack-22U-01" New-ClusterFaultDomain -Type Rack -Name "Rack-22U-02" New-ClusterFaultDomain -Type Chassis -Name "Chassis-Fabric-01" New-ClusterFaultDomain -Type Chassis -Name "Chassis-Fabric-02" Set-ClusterFaultDomain -Name Lyon -Location "France, Lyon 8e" Set-ClusterFaultDomain -Name Rack-22U-01 -Parent Lyon Set-ClusterFaultDomain -Name Rack-22U-02 -Parent Lyon Set-ClusterFaultDomain -Name Chassis-Fabric-01 -Parent Rack-22U-01 Set-ClusterFaultDomain -Name Chassis-Fabric-02 -Parent Rack-22U-02 Set-ClusterFaultDomain -Name pyhyv01 -Parent Chassis-Fabric-01 Set-ClusterFaultDomain -Name pyhyv02 -Parent Chassis-Fabric-02
To finish with the cluster, we have to enable Storage Spaces Direct, and create volume. But before, I run the following script to clean up disks:
icm (Get-Cluster -Name Cluster-Hyv01 | Get-ClusterNode) {
Update-StorageProviderCache
Get-StoragePool |? IsPrimordial -eq $false | Set-StoragePool -IsReadOnly:$false -ErrorAction SilentlyContinue
Get-StoragePool |? IsPrimordial -eq $false | Get-VirtualDisk | Remove-VirtualDisk -Confirm:$false -ErrorAction SilentlyContinue
Get-PhysicalDisk | Reset-PhysicalDisk -ErrorAction SilentlyContinue
Get-Disk |? Number -ne $null |? IsBoot -ne $true |? IsSystem -ne $true |? PartitionStyle -ne RAW |% {
$_ | Set-Disk -isoffline:$false
$_ | Set-Disk -isreadonly:$false
$_ | Clear-Disk -RemoveData -RemoveOEM -Confirm:$false
$_ | Set-Disk -isreadonly:$true
$_ | Set-Disk -isoffline:$true
}
Get-Disk |? Number -ne $null |? IsBoot -ne $true |? IsSystem -ne $true |? PartitionStyle -eq RAW | Group -NoElement -Property FriendlyName
} | Sort -Property PsComputerName,Count
Now we can enable Storage Spaces Direct and create volumes:
Enable-ClusterStorageSpacesDirect New-Volume -StoragePoolFriendlyName "S2D*" -FriendlyName CSV-01 -FileSystem CSVFS_ReFS -Size 922GB New-Volume -StoragePoolFriendlyName "S2D*" -FriendlyName CSV-02 -FileSystem CSVFS_ReFS -Size 922GB
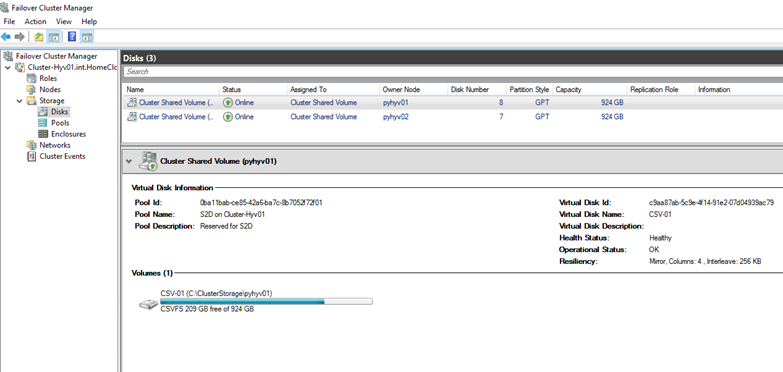
To finish I rename volume in c:\ClusterStorage by their names in the cluster:
Rename-Item -Path C:\ClusterStorage\volume1\ -NewName CSV-01 Rename-Item -Path C:\ClusterStorage\volume2\ -NewName CSV-02
Final Hyper-V configuration
First, I set default VM and virtual disk folders:
Set-VMHOST –computername pyhyv01 –virtualharddiskpath 'C:\ClusterStorage\CSV-01' Set-VMHOST –computername pyhyv01 –virtualmachinepath 'C:\ClusterStorage\CSV-01' Set-VMHOST –computername pyhyv02 –virtualharddiskpath 'C:\ClusterStorage\CSV-02' Set-VMHOST –computername pyhyv02 –virtualmachinepath 'C:\ClusterStorage\CSV-02'
Then I configure the Live-Migration protocol and the number of simultaneous migration allowed:
Enable-VMMigration –Computername pyhyv01, pyhyv02
Set-VMHost -MaximumVirtualMachineMigrations 4 `
–MaximumStorageMigrations 4 `
–VirtualMachineMigrationPerformanceOption SMB `
-ComputerName pyhyv01,pyhyv02
Next I add Kerberos delegation to configure Live-Migration in Kerberos mode:
Enter-PSSession -ComputerName VMADS01.int.homecloud.net
$HyvHost = "pyhyv01"
$Domain = "int.homecloud.net"
Get-ADComputer pyhyv02 | Set-ADObject -Add @{"msDS-AllowedToDelegateTo"="Microsoft Virtual System Migration Service/$HyvHost.$Domain", "cifs/$HyvHost.$Domain","Microsoft Virtual System Migration Service/$HyvHost", "cifs/$HyvHost"}
$HyvHost = "pyhyv02"
Get-ADComputer pyhyv01 | Set-ADObject -Add @{"msDS-AllowedToDelegateTo"="Microsoft Virtual System Migration Service/$HyvHost.$Domain", "cifs/$HyvHost.$Domain","Microsoft Virtual System Migration Service/$HyvHost", "cifs/$HyvHost"}
Exit
Then I set authentication of Live-Migration to Kerberos.
Set-VMHost –Computername pyhyv01, pyhyv02 `
–VirtualMachineMigrationAuthenticationType Kerberos
Next, I configure the Live-Migration network priority:
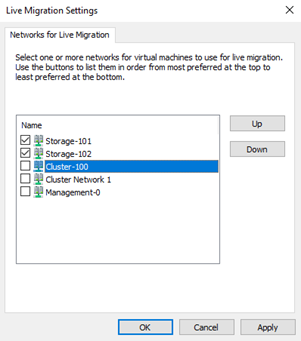
To finish I configure the cache size of the CSV to 512MB:
(Get-Cluster).BlockCacheSize = 512
Try a node failure
Now I’d like to shut down a node to verify if the cluster is always up. Let’s see what happening if I shutdown a node:
As you have seen in the above video, even if I stop a node, the workloads still working. When the second node will be startup again, the virtual disks will enter in Regenerating state but you will be able to access to the data.
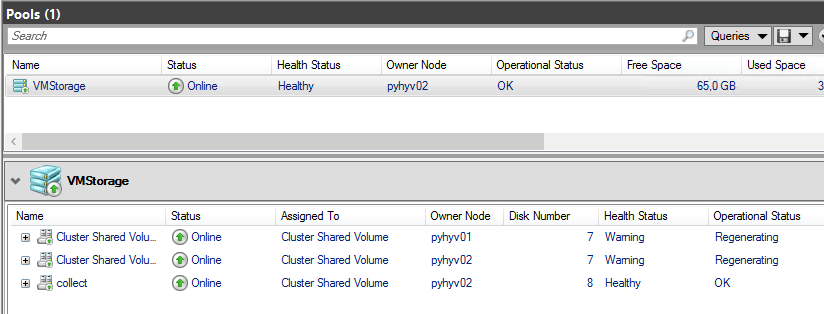
You can visualize the storage job with the below cmdlet:

Conclusion
2-node configuration is really a great scenario for small office or branch office. Without the cost of an expansive 10GB switch and a SAN, you can have high availability with Storage Spaces Direct. This kind of cluster is not really hard to deploy but I heavily recommend you to leverage PowerShell to make the implementation. Currently I’m working also on VMware vSAN and I can confirm you that Microsoft has a better solution in 2-nodes configuration. In vSAN scenario, you need a third ESX in a third room. In Microsoft environment, you need only a witness in another room as Microsoft Azure with Cloud Witness.





Hi, I have just gone through your two nodes solution, and learn a lot. I just started my test environment, so I want to get advice from you. The network configuration is too complex for me, with maybe 4 adapters, right? Can I just use one adapter to set up the test environment?
Hi,
If you have one adapter of 10GB/s for a lab it is ok. Be careful about just one 1GB/s because the solution will be not efficient at all.
Regards,
Romain
So is there a more simple way to set up a two-node, or maybe management+two-node cluster, without network configuration and active directory? I am not familiar with AD and network, and I just want to test the failover feature.
Best Regards.
To try Failover Clustering you can implement a single network with a single NIC per node. However, I recommend you at least two NICs and two networks to fully understand how works Failover Clustering.
Good Afternoon Sir,
We have used your guide to setup a cluster, however we are seeing a strange issue when copying files from a host to a LUN that isn’t owned by that node. The transfer speed starts lower then what we would expect (160 – 170 MBs) and at random intervals this drops to 0MBs for periods of a few seconds, then returns to the original speed. It will do this throughout the transfer.
We have RDMA enabled on our 10GB NICs and have also tried disabling it, but this makes the situation worse as the top transfer speed then drops to around 10MBs.
We have setup a set enabled virtual switch for the 10GB NICs on which we are running storage and production network. As documented here – https://technet.microsoft.com/en-gb/library/mt403349.aspx
Have you seen this issue before?
Thanks in advance
Hi,
I have seen this issue with a poor caching device. Could you try to disable the cache (Set-ClusterS2D -cachestate disabled) and try again ?
What kind of disk have you implemented in your solution ?
Romain.
Hi Romain,
Thanks for the reply. We have disabled the cache state as you suggested, but the problem still persists just with a lower top speed.
The disks we are using per node are;
Toshiba MG04ACA4 HDD 4tb x12
Intel SSDSC2BX80 SSD 800Gb x4
Storage controller – Dell HBA330 Mini
Thanks again
Hi,
You have 4TBx12 per node (48TB) and 800GBx4 (3,2TB) of cache. You have not enough of cache. It is recommended to install at least 10% of capacity for the cache. So in your situation, you should install 4,8TB of cache. Try to remove 4 HDD disks and try again your transfer to validate this statement.
Regards,
Romain
Try disabling SMB Signing and SMB Encryption. My test domain had this enabled by default and it meant that even though using RDMA for transfers, speeds were capped by the speed in which my CPU could decrypt the traffic.
Hi, I’ve learned a lot from this article. Thank you for taking the time to put all this down. Can I ask why none of your network configurations have a default gateway configured?
Thanks
Hi,
Because I have forgotten the argument about the gateway. I add it 🙂
Thanks, just thought I was missing something. What about the DMZ network? Can you shed some light on how you’re configuring that? Thanks.
Hi,
You just have to add the VLAN ID to the trunk (from the switches perspective) and create a VM by setting up the VLAN ID in the virtual network adapter.
Regards,
Romain
Hi,
This is a great guide. i have learned alot from this
I have a very similar build with the difference being i have a switch with 2 10Gbps SFP+ ports on it and my 2 servers also have 2 10Gbps SFP+ ports on the each.
My question is can i connect one cable from each server to the switch and then use the other 10Gbps SFP+ to connect both nodes together? is it a good idea?
Thanks
-Devlyn
Hi,
Are you sure that 2x 10Gbps SFP+ on switch are not dedicated to link between switch ?
I don’t recommend you this installation because you wil different architecture between 10Gb/s links.
Regards,
Romain
Dear Romain,
thank you for this article, this helped me a lot !
I wonder why it does have to be domain controllers on the nodes, couldn’t they be just very plain ordinary servers with the DCs then as VM ?
Cheers,
Stefan
Hi,
It is not mandatory to deploy the DC inside the cluster. If you have DC outside the cluster, it’s better. But in my lab, I have not a physical server dedicated to this role
Thanks.
Romain.
Good Morning,
I am testing your solution with our own material. Everything is going fine but I have two questions.
We have 4 ssd in each server. one 120gb to boot, one 120gb forced as journal and two 1.6tb as capacity.
S2d does not find any suitable drive for cache, do we need nvme or is there any trick to force it to use the 120 GB ?
I would also like to compare some perfs. I am using diskspd. my test vm run at 5875 iops, is that good performance or am I missing a lot ?
Many thanks for the blog, it helped me a lot.
jean-claude
Hi,
You have not enough SSD for Storage Spaces Direct to be supported. S2D requires at least four disks. If you implement cache mechanism, you require at least 2x cache disk. Moreover you need 10% of cache compared to capacity space.
The 120GB SSD is not detected as journal because you have only SSD and I think, on the same bus type (SATA ?). In this case you have to select the right disk manually.
To try performance, you can use VM Fleet: https://www.starwindsoftware.com/blog/deploy-vm-fleet-to-benchmark-your-storage-system
Thank you 🙂
Romain.
Hello Romain,
how can additional nodes added to the cluster. Is it right, that in the 2-node configuration the load on each server should not be greater 50%?
Thanks, Michael
Hi Michael,
To add a node to the cluster, you configure it as others and you add it to the cluster. Once you have added the node to the cluster, you add the physical disk to the storage pool.
In two nodes configuration, the load should not be greather than 50% to take into account a node failure (N+1 rule).
Regards,
Romain
Hey Romain,
thanks for your answer. Is it a problem to use 10G Network-Interface Card without RDMA-Feature?
Would it be possible to replace the 10G NIC (with one with RDMA) in a running system? Downtime for the replacement would be no problem.
Thank you an best regards,
Michael
Hi,
In Microsoft documentation, the RDMA is recommended especially when hosting VM. I recommend you strongly to implement RDMA from the beginning if the S2D hosts VM.
Don’t forget that Software-Defined Storage solutions rely on the network. This component is primordial to get good performance and stability in S2D. The network must be considered seriously in this kind of configuration. This week a customer bought each 10GB Mellanox double ports for 200$. This kind of NICs are now affordable 🙂
If you plan to host VM and If you can’t implement RDMA, I don’t recommend you to implement S2D.
Have a good week-end.
Romain.
Hello Romain, great article, thanks for putting it together!
I have followed the instructions and now have a 2 node hyper-converged cluster using S2D configured. Live migration of VMs between nodes works fine, but when I shut one of the nodes down then the other node looses sight of its CSV folders in c:\clusterstorage\volume1\ or whatever. Of course that means the VMs that were living in that CSV folder stop working.
Do you have any ideas why, or any advice on how to troubleshoot this? Cluster validation passes all tests fine.
My setup differs from your in that the DC the cluster nodes are attached to is at a different site and connected to it via VPN. It is also an SBS2011 DC. All routable NICs have their DNS pointing to this remote DC and can access it via the VPN, but I wonder if there is some problem due to this configuration. I also use a File Share Witness installed on a physical server 2012r2 box on the same site as the nodes are at.
If you have any thoughts I would love to hear them! Thank you for your time.
Hi,
You can contact me by E-mail and we can make a skype to show me your setup and the issue. You can find my E-mail in contact tab.
Bye.
Romain
Thank you for your kind offer Romain but at this time I will politely decline simply because I have been on the phone to Microsoft for 4 hours today troubleshooting this. We clustered the nodes, enabled s2d, configured the file witness and then created two volumes, put a VM into it, added it to the cluster and then showed that failover did not work. They used get-clusterlogs and also a microsoft troubleshooting app to take away a lot of logging and they are going to get back to me in 2-3 days with (hopefully) a solution as to why this is happening.
If this doesn’t work maybe I will ask the expert to look at my setup 🙂
Ok. I don’t want to disappoint you but it seems that Microsoft support is not yet qualified for S2D. We have had some discussions with other MVP about that. But let me know if they find the reason 🙂
Hi
I have exactly the same issue. Let me know if you will find a solution.
Regards
Mike
Hi,
Could you describe your hardware configuration ?
If I find a solution I will let you know. It is in MS’s hands now.
FWIW my setup is 2 x Dell T630s with 96 GB RAM, an 8-core Xeon with HT, 1 x 186 GB SSD for the OS, 2 x 480 GB SSDs & 4 x 4 TB HDs for the S2D storage, 2 x 10 GbE Mellanox NICs, 4 x 1 Gbps NetXtreme NICs, and an HBA330 for the storage controller. All firmware is up to date, as are drivers. OS is Server 2016 Data Center.
The two 10 GbE ports on each node are connected into two Dell S3048 switches. When we spec’d this with dell we told them they were for S2D and recommended us that S3048 switch, but it turns out it doesn’t support PFC (IEEE 802.1Qbb), ETS (IEEE 802.1Qaz) or DCBx. I don’t think this is an issue though, as I tried configuring the nodes without the switch like Romain did in his example, and exactly the same thing happened. RDMA is all enabled and working, as far as I can tell anyway.
One thing MS made me do whilst troubleshooting was to use a server 2012(r2) server to create a vHD that was presented to the network via iSCSI, then map each node onto the iSCSI HD and test fail-over like that. This worked properly, so ruled out a clustering configuration problem and pointed to S2D.
Anyway, now I await for MS’s response in 48-72 hours to see what they say. I still await a response from Dell as to the suitability of the hardware they sold us for S2D (they initially sent us a Perc730 controller for the storage controller, but in both pass-through mode and HBA mode the OS still saw the storage devices as connected to a RAID controller and so none of the HDs were eligible for the S2D storage pool.)
If you come across a fix please let me know 🙂
Hi again :),
To help you I need to check your setup and event log. If Microsoft can’t find issue, contact me by E-mail and I’ll help you.
Bye,
Romain
i see have the same issue in my lab. even when running on a nested virtual servers.
did you find a solution for this ?
did you fix it?
Yes, i have same issue in my enviroment and i can’t resolve it. If exist solution, please share it here. tnx
Vladimir
Hello,
I still have a small problem with the s2d config. I add a disk in each server making 2*112gb as cache and 2*1.46tb as capacity.
I used set-physicaldisk to force the 112gb as journal.
Here is the s2d report, it is unable to use any disk as a cache. How can I force it ? Is there any magic cmdlet ?
Disks claimed
Node
Disk
Disk
Disks used for cache
BEMERSHV10 2c97ca17-cb8b-cdfe-7348-45792843e5db ATA INTEL SSDSC2BB01
BEMERSHV10 93622255-b26e-1a79-ac4c-9a3f6a75a7d3 ATA INTEL SSDSC2BB12
BEMERSHV10 7f4b451e-a3fb-0218-37d3-19a49bd8c1fc ATA INTEL SSDSC2BB12
BEMERSHV10 b24e2404-9493-a53d-fccb-52fea7b30520 ATA INTEL SSDSC2BB01
BEMERSHV11 5a0f5599-6c98-ce50-84ea-a7f91907c74c ATA INTEL SSDSC2BB12
BEMERSHV11 42fdf210-b4f3-babb-f832-93eae638d847 ATA INTEL SSDSC2BB01
BEMERSHV11 e41f1139-01ea-87b8-35e5-724434a2a227 ATA INTEL SSDSC2BB12
BEMERSHV11 4f9f9a5f-971c-7583-591c-8e8af895fe09 ATA INTEL SSDSC2BB01
Many thks for your help.
Ps. I spoke to my boss about buying some nvme disk to have different kind of bustype in the servers, when he saw the price, he turned red 🙂
Romain – Do you have a config and setup for this type of deployment using SCVMM?
Hi,
Currently I have not. I don’t use SCVMM 2016 because, for the moment, there are too many bugs. I’ve tried to deploy it for a customer, and it caused me lot of trouble.
Regards,
Romain
Hi. Great article, thank you!
Did you run any performance tests on your 2-node cluster?
Hi,
For this current lab with consumer-grade SSD, I have 47K IOPS with 70% Read and 30% Write.
Three weeks ago, I have deployed a 2-node solution for a customer with enterprise-grade SSD based on the same design of this article. This solution provides 75K IOPS with 70% Read and 30% Write. Not bad !
Good week-end !
Romain
Hi Romain.
Can you share the detailed specs on that Enterprise-grade SSD based setup? Servers, HBA’s, disks etc.
Ulrik
Hi,
You can buy SSD such as Intel S3610 / 3710 and HBA such as Dell HBA330 or Lenovo N2215.
I would stay away from a 2-node solution. It doesn’t handle drive failures as good as you would think. I experienced this the hard way. Check out https://kreelbits.blogspot.com/2018/05/the-case-against-2-node-s2d-solutions.html if you’re interested in the details. Until Windows Server 2019 I would stick with 3 nodes minimum and always do a 3-way mirror, unless you don’t care about your data.
You know, this is based on your own experience. I have built many 2-node S2D cluster without any issues. In some case I lost the node, in other cases I lost a drives. I always recovered data. In a small company or for branch office, it is a good option.
I have 2-node setups that are going strong without issue too, it’s only a matter of time before this bites me again (and you.) You’ve been lucky if you haven’t experienced this yet. SATA drives, which S2D was specifically designed to utilize, have a failure rate an order of magnitude greater then SAS drives and SATA drives tend to die a slow death with URE after URE.
The 2-node s2d cluster handles a full node failure wonderfully. When a drive fails completely a 2-node s2d cluster handles that great too. The issue is when the drive is failing but does not fail completely. The Principal PM Manager for the high availability and storage team at MS told me that this is an area they’re working on. They’re aware of the problem and are taking steps to address it in the next version of Windows Server.
If you care about HA or your data and the use case doesn’t allow for more nodes then you’re better off handling it at the application level with two seperate servers. If you’re going to run a 2-node s2d cluster though don’t solely rely on it for data redundancy and make sure you take regular backups (you should be taking regular backup anyways.) Also, always check your storage reliability counters before restarting a node.
Note, the same applies for 2-way mirrors in clusters greater then two nodes.
Windows Server 2019 solves the problem:
https://docs.microsoft.com/en-us/windows-server/storage/storage-spaces/nested-resiliency
If you’re going to do a two node S2D cluster, Windows Server 2019 and Nested Resiliency is a must! It’s those URE that’ll get you otherwise.
This article has great details on W2106 S2D set up. Very appreciate for the detail sharing.
Some command and question:
1. W2106 S2D needs to have Switch which support RoCE (RDMA over converged Ethernet). You have set up the RDMA NIC card, but when we in our lab with RDMA enabled switch, there are still works needed to get them in sink. Once Switch and NIC connected, you will see the performance issue to enable enough Hyper-V VM. We believe there are works needed there while we are working with MS for tech support.
2. Have your configuration passed the MS W2016 SDDC (Software-Defined DataCenter) certification? Even MS mentioned that the solution can be deployed with two nodes (To be exact, we believe it is Three nodes as minimum). And for full performance guaranty, the MS W2016 S2D certification is required.
Regards,
Steve Wang
Hi,
Thank you for this kindly comment.
1. In this 2-node configuration, both nodes are directd connected for the 10GB. So I have no switch configuration. In your lab, if you use a switch, you have to configure PFC and DCB on switch side. The PFC must be set like the OS configuration. Ex: if you have set PFC to use the priority 3 for SMB on OS side, you have to set the same priority on switch side
2. Microsoft supports 2-node configuration. You can believe that 2-node configuration works plenfully.My lab is not certified by Microsoft because I have built servers myself. But I have already built several 2-node configuration which are certified by Microsoft.
Good week-end.
Romain
Thank you for the input.
We are working with MS for W2106 S2D certification and worked closely with MS S2D cert. team on the technical details discussion.
The MS S2D cert. test we have required 4 server nodes with Switch and control server set up to run and all the component used should also certified. It is good to know that you can have two nodes with network looping and get their certification as W2016 Hyper-converged solution.
Good information to have.
Thanks,
Steve
Hi,Romain. I see you just put the two 10GB together end-to-end with this two nodes. Why did this work for storage transation? I am not familar with SMB and end-to-end connection. Did you have any doc referred to SMB and network setup, so that I can learn and test? Thanks.
Hi Andes,
By default, Storage Spaces Direct takes network adapters where RDMA is enabled for SMB transaction. So I have enabled RDMA on 10GB NIC and disable it on 1GB network adapter. In this configuration, 10B/s networks handle the SMB transactions (S2D and Live-Migration).
Romain
I see, thanks. And I suppose the Mellanox Connectx3-Pro you use is a Dual-Port Adapter in each node, so that you just bind this two port together in SET, am I right?
is each port bi-directional, or one in one out?
Hi,
I have not added both Mellanox ports to a SET. Each ports are direct attached from first server to the second. So I have specified a network subnet for each link. This is standard Ethernet so there are bi directionnal.
Regards,
Romain
Hah, I misunderstand something. Thank you for pointing me out!
I almost get the server ready but I don’t know what’s the difference between my 10-Gb Ethernet adapters and RoCE adapters.
Now My network adapters are list below in one server:
lspci | awk ‘/[Nn]et/ {print $1}’ | xargs -i% lspci -ks %
03:00.0 Ethernet controller: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection (rev 01)
Subsystem: QUANTA Computer Inc Device 8986
Kernel driver in use: ixgbe
03:00.1 Ethernet controller: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection (rev 01)
Subsystem: QUANTA Computer Inc Device 8986
Kernel driver in use: ixgbe
06:00.0 Ethernet controller: Intel Corporation I350 Gigabit Network Connection (rev 01)
Subsystem: QUANTA Computer Inc Device 8986
Kernel driver in use: igb
06:00.1 Ethernet controller: Intel Corporation I350 Gigabit Network Connection (rev 01)
Subsystem: QUANTA Computer Inc Device 8986
Kernel driver in use: igb
Do I need add RoCE adapters to fit this deployment?
Thanks.
Hi,
Contact me by E-mail to explain me in deep your hardware. I will be able to advise you.
Regards,
Romain
I sent mail to s***.**m@outlook.fr. Hope to hear from you.
hi,
thanks ,a great article .
i got two questions :
1. you are using only one disk for the OS, this is kind of a single point of failure. do you have some kind of software RAID or any other kind of technology to replicate the OS disk? this is very impotent as the DC virtual machine and running of this disk
2. can you please explain what does the following commands do:
#Disable DNS registration of Storage and Cluster network adapter (Thanks to Philip Elder :))
Set-DNSClient -InterfaceAlias Storage* -RegisterThisConnectionsAddress $False
Set-DNSClient -InterfaceAlias *Cluster* -RegisterThisConnectionsAddress $False
thanks
Hi,
1. It is not a problem since if I lose a node, the storage still working. I run the DC on Hyper-V VM because it is a lab. In production situation, you should host nothing on OS disk. A physical DC is recommended.
2. These commands disable the DNS registration of cluster and storage net adapter in DNS. Sometimes, the “private” IP are registered in DNS. Only the routed IP should be registered in DNS.
Regards,
Romain
I am working on setting up a new small hyper-v cluster. my question is, when does the storage pool become available to the hyper-v host? Do I install that roll on the hyper-v servers? I have two seperate bare-metal boxes for my domain controllers, so my plan was to have hyper-v installed on a core or nano install. I just don’t know when to setup a storage pool direct cluster to use for vm storage.
Hyper-V builds
2*Xeon E5-2670 8 core processors
2* 250GB raid 1 7200 rpm OS disk(s)
16*4GB Quad-Channel ECC Mem
2 * 480GB SSD disks
4 * 1TB mechanical disks
Also, are you saying that two ssd disks is not enough disks for storage pools direct? I feel like 4 ssds in each machine is a bit excessive for our needs. My main question, again, is when do i add all the drives to the storage pool to use for host vhdx files. I’m trying to avoid building a dedicated bare-metal SAN for storage being used exclusively by hyper-v.
Hi,
First I don’t recommend you Nano Server for Hyper-V or/and storage. Secondly, you have enough SSD in your configuration because you have 10% of cache or more regarding capacity.
If you follow my topic, you see that I enable storage spaces direct on the cluster and so a Storage Pool is created.
Regards,
Romain
Hi. Great article, thank you!
Need a SAS HBA adapter for S2D?
thanks
Hi,
Yes you need a SAS HBA Adapter (a RAID adapter which works in non-raid :)). Exemple:
Dell: HBA330
Lenovo: N2215
Regards,
Romain
Why do you advise the HBA adapter, although you do not use it in your configuration?
Hi,
The presented configuration is a lab and it is located in my restroom 🙂 I use a SATA Controller which is not supported in production because of lack of functionality compared to SAS controller (disk location for exemple).
However I advise you these HBA because I have deployed production environment and I have used these one.
Regards,
Romain
Can you explain why you setup 2 storage networks and 2 CSV?
Thanks
Steven
Hi,
I setup 2 Storage Networks for redundancy and bandwidth (SMB MultiChannel). Then I create two CSVs in order that each node manage a CSV to balance the workloads.
Regards,
Romain
Hi,
I’m doing my research before I setup our S2D cluster and see a contradiction here.
You said in the Article text: “I can’t leverage Simplified SMB MultiChannel because I don’t have a 10GB switch. So each 10GB controller must belong to separate subnets.”
But just here you say you’ve setup two of them “for redundancy and bandwidth (SMB MultiChannel)”
So I’m confused. I don’t understand why a 10Gb switch matters in order to get SMB Multichannel working. Was that an early misunderstanding on your part that survived to publishing?
We’re going for a small 2 node S2D cluster and it didn’t make $ sense to purchase a 25Gb switch (or 2 for redundancy!) for the storage network just to connect 2 nodes together. So I’m just using DAC cables between the 2 nodes with a dual port 25Gb Adapters. But I’ve dual port adapters so figured I could push the storage throughput to 50Gb with SMB Multichannel.
Other articles I’ve seen suggest creating a virtual switch on each host and adding the two physical NIC’s to it (Switch Embedded Teaming) and you then add two virtual NIC’s (Management OS enabled) each bound to a different physical NIC to get two interfaces that are each connected to a single virtual 20Gb switch – Which you could then put on the same subnet to get SMB Multichannel to work happily…
I might be missing some crucial bit of understanding as I’m not sure why you bother doing all this unless the fact that the virtual NIC shows that its now 50Gbps will have a real effect on the S2D speeds. I guess I can try it both ways and test for any speed difference with VMFleet.
Regards,
Adam
Hey,
They are two things:
– Simplified SMB Multichannel: enables to detect network topology and add all SMB network adapters in a single subnet
– SMB MultiChannel: leverages several NIC (or vNIC) to handle SMB traffic
Because I have no switch, I can’t add all network adapters inside the same subnet and so I can’t leverage Simplified SMB MultiChannel. However I use SMB MultiChannel.
The typical configuration I implement with two 10/25/50/100 NICs:
– I create a Switch Embedded Teaming with both NICs
– I create a Management vNIC without RDMA
– I create two SMB vNIC each bound to a physical NIC and with RDMA
In your configuration, you don’t have a 10GB/s switch. So you must deploy the following configuration:
– Each 10Gb/s NIC in a specific Subnet with RDMA enabled
– On 1Gb/s NIC, create Switch Embedded Teaming, create a vNIC for management. VMs will be bound to this vSwitch.
I hope I was clear :p
Hi,
Ah the difference between “simplified” and “Simplified”.
I thought it was just an adjective. Thank you for clarifying.
I’ve followed your “typical configuration” for my 25Gb/s NIC’s. But your last paragraph doesn’t make sense to me. You switched to saying 10Gb/s, but I’ll assume we’re talking about my 25Gb/s storage NIC’s.
Why do I need to put each 10(/25)Gb/s NIC in a specific subnet with RDMA enabled? You didn’t mention anything about SET here and you did for the 1Gb/s so why would I not follow your “typical configuration” and just using SET on them?
Is SET bad for performance and you recommend just relying on SMB Multichannel for the storage network?
Hey,
You told me that you don’t have a 10/25 Gb/s switch(es). In this way, you have to direct attached both servers and you can’t use a SET switches and you have to dedicate 10/25 Gb/s for Storage and Live migration.
If you have a 10/25 Gb/s switch(es), you can create a SET with both NICs and create a converged network.
Can’t??? (as in the “…can’t use a SET switches and have to dedicate…”)
Because I have a working setup downstairs right now. Two Servers with dual port 25Gbps NIC’s connected to each other by DAC cables for the storage back end. On each server I have added the 2 adapters into a virtual SET switch, created two SMB vNIC’s, added RDMA and mapped each to its physical NIC. They appear to communicate just fine with each other and VMFleet on the S2D cluster is showing over 300,000 IOPS per server. (NVMe disks – we haven’t skimped there)
I don’t recall reading anything anywhere saying SET had to involve a physical switch. SET is in Switch Independent mode automatically, right? No option to use LACP or Static Teaming. And Switch Independent mode means that it makes no assumptions about the switch – which is good because I don’t have one.
Before I read any guides online I had already put all of the 25Gbps NICs into the same subnet – 192.168.253.0/24
If I pinged either of the two addresses in this subnet of the other server, it always worked. I never saw a single dropped packet and later after I had read your article and others I wondered if SMB multi channel was stepping in at either end to ensure packets got to where they were meant to be?
Anyway, no need to take my word for it. Try it out for yourself. And BTW, thanks for the whole article. Very helpful to have a real world guide as well as the Microsoft documentation.
If in your solution NIC 1 is connected to NIC1 of the second server and NIC 2 connected to NIC2 of the second server. If you create a SET switch with NIC 1 and NIC2, how it works if NIC1 of the first server and NIC2 of the second server is down ?
You mean two independent failures? You’re absolutely right. It won’t. But then that same occurrence would bring down your solution of having the two in different subnets, so your point isn’t toward resiliency.
I just like that I end up with 1 storage subnet at 50Gbps. The setup is then standardized so its the same for all servers regardless of having a storage switch or not, and more scalable in that if we ever do get that third node and storage switch then I can just plug it in.
What I wanted to say, is that NIC 1 can communicate with NIC2 if both are in SET and it can’t because of the physical topology. Each time I talked with Microsoft, they recommended the configuration that I presented.
Hi
almost got it runnging but Enable-ClusterStorageSpacesDirect gets stuck in 27%. Yes, I cleaned the disk. Out of ideas.
Well, I tried everything until I thought to shut down the cluster while Enable-ClusterS2D was hanging on 27%. After starting cluster again and running Enable-ClusterS2D again, it worked. So finally i can continue whit my testing. I hope MS will fix it because this is not recommended for production enviroments.
Hi,
I have had this issue also. When this issue happens, I cancel the Enable-ClusterS2D, I reboot all nodes and I run Disable-ClusterS2D. Then I run agian Enable-ClusterS2D and it works.
Regards,
Romain
Romain,
Thank you for the article. Do the nodes need to run Windows 2016 Datacenter Edition, or can this be implemented with Windows 2016 Standard edition?
Hi,
Windows Server 2016 Datacenter is a requirement for Storage Spaces Direct.
Regards,
Romain
Romain,
Thank you for the response. Do you have any experience with software based vSAN solutions like Starwind? For a 2-node cluster with less than 14 virtual machines, paying 6K+ per node for a license is a bit much.
If 2016 Datacenter is a requirement for S2D, then I’d argue that this really isn’t a great solution for small business!
Hi,
It depends of the small business. If small business needs to host 20VMs, this solution is good. If the small business needs to host 4 VMs, I’m agree.
Hi Romain,
I see you are using 1 NVMe per node as cache. This technet article states that you need 2 NVMe cards.
https://technet.microsoft.com/en-us/windows-server-docs/storage/storage-spaces/storage-spaces-direct-hardware-requirements?f=255&MSPPError=-2147217396
Can you clarify how this works?
Hi,
This is because it is a lab. I have build this configuration with my own money and NVMe are expensive. But I’m agree, in production, if you implement mix storage devices like SSD + HDD, 2 cache devices are required.
Regards,
Romain
Is the second NVMe for redundancy only? If so, what would happen if the NVMe fails on one node?
i’m curious about this as well, lol. I have two nvme drives, but only two slots on the board and one is filled with a 10GbE card.
You need two cache devices for the redundancy. If a cache device fails, the other can handle the cache for all other capacity devices. This is a requirement from Microsoft.
So how are you able to use 1 NVMe drive? This is non-production & backedup using veeam.
This would give me 1 512GB NVMe, 2 800GB SSDs, & 2 3TB drives per node.
the solution works with only one cache device. It is not supported by Microsoft. If it is for a non production environment as mine, you can work with one cache device. If it is production environment, don’t go with only one cache device.
Thank you for taking the time to type out this very detailed guide. You are a rock star! I’ve learned a lot just by trying the steps out a few times. I have a question for you… Does your server setup support SCSI Enclosure Services? When I went through the steps with my 2 Dell Poweredge R730s I managed to get it up and running. It is super-fast. But whenever I down Node number one, the whole CSV fails until the 1st node comes back online. Everything I am reading about this points to the fact that my servers do not support SCSI Enclosure Services. I am curious to see if this is a setup problem, or does my hardware truly not support Storage Spaces. Thanks to everyone for their posts and input!
Thank you very much :). I don’t know why the cluster is down when the node is shutdown. Maybe I can check your cluster by skype ?
Hi Romain!
I have production env. and issue that i cant solve. Do you have experience with that kind of a problem? Get-PhysicalDisk result on one disk:
FriendlyName CanPool OperationalStatus HealthStatus Usage Size
———— ——- —————– ———— —– —-
ATA MB8000GFECR False {Removing From Pool, OK} Healthy Retired 8001524072448
I cant reset this disk or fix this. What can be done?
Hi,
Your disk is marked as retired. to change this you can use the following cmdlet: Set-PhysicalDisk -Usage AutoSelect -UniqueId ID
Not getting better:
OperationalStatus HealthStatus Usage Size
—————– ———— —– —-
{Removing From Pool, OK} Healthy Auto-Select 7.28 TB
Have you tried to physically remove the disk from the node and add it again ?
Hi. Its complicated to locate physical disk – LED identification script in PS is not working. Heres what helped me:
Get-StorageFaultDomain -Type StorageScaleUnit | ?{$_.friendlyname -eq “hv0”} | Disable-StorageMaintenanceMode
Whit this command you can basicly hard-reset the disk. First, set disk as retired.
Question for you regarding backup.
How compatible is using something such as Storage Craft Shadow Protect installed on one or both physical units to backup to a NAS?
That has been my difficulty with SoFS in 2012 is finding a good backup solution to backup the CSV shares. 🙁
Why you want to backup shares ? you can backup virtual machines from host with solution such as CommVault, Veeam Backup & Replication or System Center DPM.
Hi, Romain, it is a long time since I last ran my hyperconverged environment. I investigate Hyper-V 2016 features and consider that I can run free backup like replica to other host, using resilient change tracking feature, known as RCT in Hyper-V 2016. Can I? I just want to incrementally backup one of my VHDX file for the first step(in a single file). I tried to check some APIs but without luck. Any advise will be much appreciated. 😀
Best Regards
Andes.
In fact I check veeam, CommVault too, but this is too large and complicated for me, because I just need to run a small agent to sync the file(maybe).
Hi,
I know this question was asked a while ago, however I’d like to share my good (long-term) experiences with Altaro VM-Backup. It is lightweight, easy to setup and does a great job backing our hundreds of VMs with high-speed and excellent deduplication/compression ratio. It is a good fit for small setups up to larger clusters. Last but not least they have a really fair pricing (compared to e.g. Veeam or CommVault) and a great support team.
(I am a customer/user of this product, not a dealer or otherwise affiliated with Altaro)
Regards,
N.
Likewsie I have been using Altaro VM Backup for a few years now, and agree setup takes a few minutes, its fast, easy to use, also teh deduplication/compression ratio is excellent. After using Veeam for a number of years, once I discoverd Altaro VM Backup I have never switched back, added there is also a free version also. And if needed you can also backup to Azure if you purchase the unlimited Plus Edition. Awesome program.
I have a question about this setup.
I have 2 DELL servers
DELL PowerEdge R730xd Server
64GB RAM
PERC H730 Integrated Mini RAID Controller
2, 200GB 2.5″ SSD in RAID-1 in Flex Bay for OS
4, 2TB 3.5″ Hard Drives in RAID-10
Broadcom 5720 QP 1Gb Network Daughter Card — 4 x 1GB port
Intel Ethernet X540 DP 10GBASE-T Server Adapter — 2 x 10Gb ports
the only difference between them are CPUs
one is Dual Intel Xeon E5-2620 v3 2.1GHz
and the other is Dual Intel Xeon E5-2620 v4 2.1GHz
I run a Windows server 2012 R2 Hyper-V failover cluster on them
using StarWind vSAN to mirror the DAS and provide iSCSI shares for CSVs
what would be the best and safe way to convert this setup (this is a production unit)
to Server 2016 Hyper-V failover cluster with s2d instead of hardware raid and starwind?
is it possible?
thanks
Hi,
Your hardware is not ready for S2D. The PERC H730 is not supported because it can’t passthrough disk to Windows Server. Even if you set JBOD mode, the disks will be show up to RAID bus. There is not enough of memory also. S2D requires 128GB and you need SSD cache devices.
So the best way is to buy to S2D ready node and deploy it on top of them. Them yo uwill be able to migrate VMs.
Regards,
Romain
I have a functional 4 node storage spaces direct hyperv cluster in place and has been running great for the past few months with 10Gb 2-port cards in each host(not RDMA capable). My boss let me get some spiffy 10Gb 2-port cards to add to each host which support RDMA. My initial thought was that I would continue using the non RDMA cards for the commodity vm data network and management, then use the RDMA capable cards for cluster and migration traffic.
You seem to have a better grasp on the optimal network setup.
What would you do in my situation?
Hi,
In your situation I’d add RDMA NICs in each servers. Then I’d set the network on these new ports (new subnet, new vlan). Then the cluster is enough cleaver to take RDMA network adapters for SMB (SMB Direct, SMB MultiChannel) and that’s all 🙂
Romain,
There is the Microsoft School of thought that pushes setting up a teamed virtual network for hyper-v
https://leandroesc.wordpress.com/2015/04/26/configuring-the-virtual-network-using-converged-networks/
How does that compared to having specific redundant adapters for live migration, management, etc.
Have you done any tests comparing overhead, etc. ?
The intended environment is for a 2 node cluster, using starwind for a virtual dc, file server and db server
Hi,
The topic you show me is based on 2012R2 and set doesn’t exist this version.
You can use 2 network adapters for cluster networks (Live-Migration etc.) and two for VMs. It is up to you. But if you have 2x 10GB/s with few VMs you should converge everything. It’s depend on your infrastructure.
In many design, I converge everything in two 10GB/s / 25GB/s network adapters. Then I create virtual network adapters for cluster. Usually I don’t isolate cluster, live-migration and storage in several vNICs.
Hey Romain,
Great information. Can you go into a little more detail about the configuration of the networks inside of Failover cluster manager? For the “Cluster” network, are you configuring cluster and client communication? What are you doing with Storage and Management?
Also, current setup is 2 nodes, and in each server are the following
196GB of ram
8x1TB HDD
4X500 SSD Intel DC S series
2×500 NVME Samsung 960
I was getting extremely poor write speeds. I believe it was due to not enough cache? in my current scenario, I would need more cache or do you think it is the samsung 960s not doing well? with cache enabled i get around 30-50 MBs with it turned off, I get around 200Mbps and random peaks of 600 Mbps. RDMA perfmon counter was showing hits, but then it just stopped.
Hi,
The management network is set as cluster and client and SMB networks to cluster. You have poor performance because of NVMe. These NVMe are for consumers. You need enterprise NVMe such as Intel P3710.
Regards,
Romain
Hi Romain,
Good Article, but i’m struggling on a few points on the network side, for our instance we have our local lan (management/AD etc) on 192.168.16.0 /24 | Storage 1 on 172.10.10.0 /24 vLAN 103 | and Storage 2 on 172.11.11.0 /24 vLAN 104.
We have a 10GB link to the network for the VMs to utilise etc, however I cannot communicate from say node01 with management IP of 192.168.16.9 with the rest of the network. Have i missed something, presume you need to bind vEthernet Management with the physical 10GB link?
Could you contact me by E-mail to expose your configuration please (rserre at seromIT . com) ?
Hi Romain, can you compare it again Starwind virtual SAN? Thank you!
Hi Romain,
Awesome article. You may want to add “-f” to your ping command for testing jumbo frames as they will automatically be fragmented if it exceeds the MTU.
e.g. ping 10.10.101.5 -l 9000 -f
Unless there’s something I’m not familiar with on the 10Gb/RDMA/RoCE setup that Windows treats differently.
Thanks!
Jeremy
Great article, just setup a couple of 2 node clusters from different vendors for evaluating, no 10gb switches in our environment so this article was a massive help
Romain would you say 170,000 IOPs total on the cluster is good for this type of setup. At 70/30 4K
All servers have the same config
2×240 SSD and 4×600 sas
Interesting that not all vendors hardware is giving the same speed, guessing this may be down to 2 factors slower hardware is using 2.5 10k sas and the faster units are using 15k sas for the capacity
The other factor might be the SSDs themselves and what they shipped in the servers
Hi,
Can I do this without using SSDs? I need to do this setup for a small organization with little money, so SSDs are not an options. only can afford SAS
Hi,
No this is not possible. With HDD, you must use flash devices for the cache (NVMe or SSD). In almost all hyperconverged solution, you have to buy SSD for caching.
Do you have sample to perform hyper-converged using Windows 2016 desktop experience?
Hi,
I avoid to deploy Desktop exprience with Hyper-V. Can you imagine an ESXi with desktop experience ?
I can’t see advantage of desktop experience. Lot of Hyper-V with desktop experience have crapware installed on it and browser such as firefox.
I prefer to deploy Core edition to reduce the ability to deploy application on hyper-v and to reduce patch impact. The reboot is also faster than desktop experience.
In my opinion, Desktop experience should be avoided on Hyper-V and storage.
Romain
The best-written article of this type I have ever seen. The devil is in the details, and there are plenty of those here. I love the scripted (repeatable, documented) approach. My sincerest thank you.
Thank you very much 🙂
Great article. But unfortunately I don’t have SSD just 10 SAS drives. I will give it a test anyway. My setup will have 3 nodes 4 10GB X520 DGA nics and a 10GB Unifi switch as well. I will also setup nic teaming for VM Workloads and VM Migration using the 4 interfaces.
Curious if you’ve gotten this setup yet? Sounds similar to a setup we are looking at.
Not as yet still working on it. Will update when I do.
Hi,
Sorry I just saw your comment. You can’t implement S2D with HDD without SSD. It is not supported. If you choose to implement HDD? you need at least 2 SSD per server (depending on ratio). Sorry man 🙂
Hello Romain,
Why do you say we can’t implement S2D without SSD? May be, it is not supported, but it is possible. I have one.
I said that because if your capacity devices are HDD, you need SSD (at least two per node) for cache.
You can also implement a full-flash solution. In both case, you need SSD to be supported and to get performance
You can deploy s2d without cache. Yes, no one would recommend it but as for me it’s ok for small deployment or testing.
You can do everything in testing environment. But in production, you can’t deploy S2D without cache if your capacity devices are HDD (even for small deployment). It is not supported and the performance will be poor.
Hi Romain,
Great article 🙂
The question about VMQ.
I see, your configuration basis on 6 physical cores/12 logical:
https://ark.intel.com/products/75789/Intel-Xeon-Processor-E5-2620-v2-15M-Cache-2_10-GHz .
In your description, I see, you take 1,2,3 for the Storage 1, 4 and 5 – Storage2.
But in the config, you skip the core 1 (that’s correct and recommended), but for then you take the Cores 2 and 3 for the Strorage 1 (starting from base CPU – 2, 2 CPUs – that corresponds to cores 2 and 3, and the Max is 4 – that sounds correct), then 4 and 5 (base is 6, 2 CPUs, and Max is 8 – that matches to 4 and 5).
Probably, you have to correct “# Core 1, 2 & 3 will be used for network traffic on Storage-101”. Am I right?
I am just curious: what do you do with the core 10 and 11 🙂 ?
Just going through your comments, I realized, I have PERC H730 with RAID10, but it looks like the workaround is already published (we say, not for production 😉 ). It’s a little bit insane, how the hardware is too much dependent to the software those days. People have drop away quite expensive stuff to take S2D on the rig. Unluckily, it is not that “unlucky” trend over here only. The simple example, you can see, how people are abandoned with the support of smartphones, with the bitten apple for example, using older models. You just cannot update the system and you are exposed by vulnerability, even the phone is fully functional, and you spent the fortune past days to buy that older one. That’s quite sad. Probably thousands of people have the same feeling, but none (except some individuals) can say that a little bit louder.
Cheers,
Marek
Hi,
The number of VMQ must be the same on NICs/vNICs with the same usage. THis is why I don’t use 10. In production, We have usually two CPU with more Cores. In this case usually I set 8 VMQ / RSS per NIC/vNIC which need these technologies.
Hyperconverged solution is a bit complicated than smartphone. Hyperconverged solution required HBA in JBOD because this is the operating system which managed the resilience. If you leave RAID and then S2D, you lose a lot of I/O. We implement storage solution, this is why it is hardware dependent.
For sure, hyperconverged solution are easier to manage than hardware solution such as SAN, RAID, NAS and so on.
Is the toilet (as pictured) required?
Absolutely. This is a requirement for S2D. In case of production, I recommend you two toilets for high availability 🙂
haha…!! 😉
Hi Romain,
just for my interest, is it possible to create an S2D Hyper-V Cluster with the following configuration:
2 HP Blades each:
2x 120GB SSD for the System
1x 1TB SSD for S2D
I know this is absolutely unsupported and not recommended, I’m just interested if S2D would allow creating such a cluster in general, since there is no local disk redundancy per blade.
Thanks!
Robin
Hi Robin,
Really not sure if it’s work with a single disk. If you want to try the solution, deploy somes VM with virtual disks and then enable nested virtualization.
how has this performed over the last year running those non enterprise SSDs? Do you run much VM workload on it?
I had to change SSD because they was weared out. I change them by Enterprise SSD Intel S3610 :p
Hi Romain,
I’m performing a clean shutdown on my S2D Hyper Converged environment tomorrow, presume its the same on 2016 as on 2012 R2?
Process being, shut down cluster via the failover cluster manager, once complete, shut down node02 and then node01. Once i’m ready to power back on, power on node01 and then node 02 and start the cluster from failover cluster manager?
Hi,
Yes and the cluster start himself when the nodes are online.
Can you grow a 2-Node cluster to 3 at a later point with S2D? i.e. initially it’ll mirror two ways, is it possible to change the protection to 3-way mirror online or is that destructive?
Phenomenal blog, by the way – it’s been the most educational way to learn about Failover Clustering for me – very concise and clear. Thanks for taking the time!
Hi Greg,
Thank you very much. Unfortunately, you can’t move a 2-way mirroring to a 3-way mirroring. You have to remove the volume and recreate it to 3-Way.
Hi Romain,
Thanks for this article, it’s proving to be really helpful
I’m setting up a 2 node S2D test environment and hope to go live with it after testing. My setup is;
2) HPE DL380 Gen9 server, with 4) 240gb SSD, 20) 900gb SAS, 2) 2TB SATA for OS. 192gb ram. Each server has dual port Mellanox ConnectX-5 100gb qsfp28 ports.
Each server has an HP 440ar controller connected to 8 drives, an HP 840 controller connected to 16 drives and the two OS SATA drives are connected to the onboard controller for booting the OS.
In addition to the ConnectX-5 adapters, each server has 4) 1 gb onboard nics and 1) dual port 10gb nic.
Right now the 1gb nics connect to an HP Procurve 2510g-48. The two 10gb nics connect to a netgear 10gb switch.
I connect the ConnectX-5’s together with twinax DAC, no switch.
If you could make the time, I could really use some help in setting up the network for S2D. When I run Cluster Validation with both of the Mellanox CX5’s connected to each other, the cluster validation fails the network test, However, when I disconnect one of the CX5’s, the network test passes.
If you haveany other suggestions about how to get the most out of my setup, please feel free to make suggestions on ways to improve it.
Thank you
This is the network failure message from the cluster validation test;
Network interfaces VMHOST1.test.com – Mellanox 1 and VMHOST2.test.com – Mellanox 2 are on the same cluster network, yet address 10.10.101.13 is not reachable from 10.10.101.10 using UDP on port 3343.
Network interfaces VMHOST1.test.com – Mellanox 2 and VMHOST2.test.com – Mellanox 1 are on the same cluster network, yet address 10.10.101.11 is not reachable from 10.10.102.12 using UDP on port 3343.
Network interfaces VMHOST2.test.com – Mellanox 2 and VMHOST1.test.com – Mellanox 1 are on the same cluster network, yet address 10.10.101.10 is not reachable from 10.10.101.13 using UDP on port 3343.
Network interfaces VMHOST2.test.com – Mellanox 1 and VMHOST1.test.com – Mellanox 2 are on the same cluster network, yet address 10.10.102.12 is not reachable from 10.10.101.11 using UDP on port 3343
At first I created the two networks mentioned in the article (10.10.101.0 and 10.10.102.0) but after failures, I tried others. Not sure why it fails when I have both ports on CX5’s connected to each server, but passes when only one of the dual ports is connected.
Contact me at rserre [at] seromIT [dot] com.
Hi Romain
I have the same issue like Damon Johnson have you a hint for me.
best regards
Hi Romain,
I also have the same problem as Damon Johnson and firewall disabled completely. If I put hosts in differnet subnets they pass the cluster validation but fail to create the cluster due to following error in the cluster log:
‘INFO [NODE] Node 1: New join with n2: stage: ‘Attempt Initial Connection’ status (10060) reason: ‘Failed to connect to remote endpoint 10.63.37.5:~3343~’
I emailed you as suggested and would appreciate any help or advice you may have with this.
Thanks
Forgot to say I have also posted issue with UDP 3343 here: https://docs.microsoft.com/en-us/answers/questions/249241/cluster-network-validation-fail-udp-port-3343.html?childToView=257695#answer-257695
I worked it out thanks to this article. Instead of using a single physical NIC for management traffic, I used a SET with a virtual management adapter across both servers and cluster worked. No more issues with UDP port 3343. Thanks Romain 🙂
This is the network error message from Cluster validation;
Network interfaces VMHOST1.test.com – Mellanox 1 and VMHOST2.test.com – Mellanox 2 are on the same cluster network, yet address 10.10.101.13 is not reachable from 10.10.101.10 using UDP on port 3343.
Network interfaces VMHOST1.test.com – Mellanox 2 and VMHOST2.test.com – Mellanox 1 are on the same cluster network, yet address 10.10.101.11 is not reachable from 10.10.102.12 using UDP on port 3343.
Network interfaces VMHOST2.test.com – Mellanox 2 and VMHOST1.test.com – Mellanox 1 are on the same cluster network, yet address 10.10.101.10 is not reachable from 10.10.101.13 using UDP on port 3343.
Network interfaces VMHOST2.test.com – Mellanox 1 and VMHOST1.test.com – Mellanox 2 are on the same cluster network, yet address 10.10.102.12 is not reachable from 10.10.101.11 using UDP on port 3343
At first I input the addresses mentioned in your article ( 10.10.101.0 and 10.10.102.0 ) but after it kept failing I tried other configurations.
Still not sure why the network fails validation when both ports of the ConnectX-5’s are connected to each server, but it passes when I connect 1 port.
Hi,
What is the licensing cost for this model, our company already have a number of 2016 DataCenter, does HA and hyperconverge need extra licensing ?
Also can I set up this lab on a laptop running Windows 10? my intention is to setup a demo on my laptop running 2 HyperV hosts on 2 VM …
Thanks
Hi,
Windows Server 2016 Datacenter provides everything you need for hyperconverged infrastructure such as Hyper-V, Storage Spaces Direct, Storage Replica and so on.
You can deploy a S2D lab on your Windows 10 🙂
Hi Romain,
first thing thanks for this brilliant article – clearly one of the best I have seen in this context!
I’ve built a 4-node S2D production cluster earlier this year and everything is fully functional, however I am suffering from extreme write latencies (200ms +) when some more serious write load is applied. Even a single file copy to one of the cluster volumes can cause this phenomenon. The hardware (per node) is comprised as follows:
Supermicro AS-2023US-TR4
2x AMD EPYC 7451 (24 core)
512GB RAM (@2666MHz 1DPC)
2x Samsung PM1725a 3,2TB NVMe AIC
8x Seagate Exos X X10 10TB, 4Kn, SAS 12Gb/s
1x Intel X540 10GbE Dual-Port NICs (Management, Hyper-V Network – SET Team)
1x Mellanox 100GbE Connect-X5 Dual-Port RoCE , “host-chaining” enabled – no external switch, as nodes are directly interconnected in a “ring” fashion.
I have primarily my network setup under suspicion, since there is no useful information available how to properly setup such topology with S2D. Every other setup seems to completely rely on external switches… However with the very latest firmware from Mellanox I am at least able to verify that the nodes can talk to each other in a very decent speed (50-90Gb) and that the setup is tolerant against a connection or complete node failure. Also S2D uses the connection as expected and I am getting good read-pattern results with VMFleet (~650.000 4k iops), however once I am increasing the write ratio, the write latencies go through the roof.
After having tried a lot, I am currently out of ideas…
There’s nobody at MS you can ask and also the very friendly and helpful Mellanox support was out of ideas in this special scenario with S2D and host-chaining. From their perspective it is basically all good.
I know it was a little bit venturous to try this setup, however it is so much appealing in terms of cost/performance that I couldn’t withstand once Mellanox presented the Connect-X5 and featured the all-new switchless interconnect option.
Another area of suspicion would be the PM1725a NVMe which is a race horse on paper, however I see that S2D disables the devices’ build-in write cache which might cause the adapter to stall after a short period of write pressure. What I usually see is that everythig starts fast for a few seconds and then slows down extremely – showing the mentioned extreme write latencies (using watch-cluster).
Do you have any idea in what I should further investigate?
Or a hint whom I could ask?
Thanks in advance and many regards,
N.
Hi,
First question, this hardware is certified for S2D ? especially hard drive and SSD ? You can contact me by E-mail in order I try to figure out the issue 🙂
Hi Romain,
basically everything but the NVMe SSDs of type Samsung PM1725a are certified for S2D… however, regarding specs they should be more than just fine… (but who knows)
Cheers,
N.
Hello,
This is a great post, I’ve used a lot of Poweshell commands and best practices of your site.
Maybe one major tip: you should use Windows Server 2016 Datacenter LTSC, so you can’t use 1709 or 1803!
https://docs.microsoft.com/en-us/windows-server/get-started/server-1803-release-notes
One question: you rename the “Cluster Network 1” (and 2,3,4) to “Storage-101” etc. But how do you know which number belongs to which NIC/network? I’m using Powershell only.
Thanks,
Marcel
I know by looking the failover cluster manager: there is the network subnet.
I was trying to use PowerShell to find this out, this is because I didn’t had a server with Failiover Cluster Manager yet.
So you can compare the metric value. A lower metric value means RDMA network adapter 🙂
Hi Romain,
Can I ask what software you used to draw your hardware implementation.
Thank you
Sure: Visio 🙂
Hello Mr. Serre,
first of all: your blog is a REVELATION. I recently took the position of Administrator at a moving company, which had no IT-department before. Since Im doing the job alone, I demanded HA. Doesnt matter how, but I will not lie awake at night and mumble “please dont break, please dont break, please dont break” – so HA is the way.
But even in a traditional Hyper-V cluster, the shared storage is always the Single-Point-Of-Failure. So I got into hyperconverged solutions and therefor Storage Spaces Direct (and VMware vSAN, but thats too expensive).
I also considered StarWind, but after testing the trial versions and S2D in lab environment, I will go with S2D because of the streamlined usability (or do you recommend StarWind as well?).
Its a 2 node operation and mainly needed for the new ERP system, which comes in July. The rest of the physical servers on-premise will be virtualized at some point in the future and also placed on the S2D cluster (all in all about 10-12 VMs). Its not that big environment, just 10 employees, although we will expand 2019 into a new plant and then we will need the extra power S2D provides (new customers, new employees etc.)
Ok, so much for that. If it is not too much to ask or an imposition on your person: would you mind having a look at my server configuration?
Thats for one R740 Node:
2 x Intel Xeon Gold 6134 Processor 3,2 GHz, 8C/16T
64 GB RAM
4 x 1,2 TB SAS 10k HDD (maybe getting instead the 1,8 TB drives?)
2 x 480 GB Intel S4600 SATA SSD
Boss Controller – 2 x M.2 Sticks RAID1 for OS
HBA 330
1 x Mellanox Dualport ConnectX-4 LX 25 GbE (RDMA)
1 x Intel X710 10GbE Dualport (production LAN)
In the beginning its only for 4 VMs – 1 domain controller (2nd physical – for now), 1 wsus server, 1 print server and the ERP system (the ERP system has a progress database included in its setup).
What do you think?
Thanks in advance and best regards,
Best article so far! Romain, between this and a hyperconverged infrastructure like nutanix or simplivity, the pros and cons, cust x benefit, what is your opinion?
Hi,
The greatest pros for S2D is performance. I’ve never seen competitors get the same level of performance than S2D. Another advantage is the price: S2D is less expansive than other competitors.
However Nutanix brings simplicity and VMware brings an innovative resiliency management model. I think today, enough solutions exist to please everyone 🙂
Hello Romain and my respect for the article and comments.
I humbly ask for my two questions answering:
1. You say that S2D is less expansive than other solutions. But Datacenter edition’s cost about 6k$ x2 nodes=12k usd. If we be able for example to consider junior starwind solution it cost about 2.5k for two hyperconverged nodes and 4 Tb replicated storage (+hyper-v free edition). What can you say about it?
2. Could you also give advice which case two 10Gbps mellanox double port cards (for HA) won’t be enought and there is needed 25Gbps? As i understand correct, live migration is essentially migration RAM data from one node to another. So, if it’ll be 256Gb RAM on each node, live migration will take (very rude of course)
256 Gb / (10 Gbps / 8) = 205 sec
or
256 Gb / (25 Gbps / 8) = 82 sec
Please correct me.
Hey,
1. When you buy Datacenter edition, you buy also Hyper-V and licenses for guest VMs, S2D, SDN, and so on. Even if it’s expensive, you get access to all Windows Server features inside VMs.
2. The 10Gb networek adapters are used for Live-Migration and S2D. An SATA SSD works almost at 500-600MB/s. You can easly see that 4 SSDs can use the whole 10Gb/s bandwdith. Morevoer Microsoft recommends now 25Gb/s network adapter in their documentations.
I hope I helped you.
Hi Romain,
Thank you for this website which is a mine of information!
I was able to test the s2d with 2 vm Hyperv and one for the quorum. it works well except when a node fails I have no automatic switch VM node1 to the node2…the storage cluster continues to work I still have access to data but the VM does not restart wait 5…10min and nothing.
The question is: with 2 nodes it is possible to automatically switch vm from node 1 to 2 or vice versa when a node disconnects after a failure?
Hmm it’s strange because the VM should restart on the other without any issue. Did you notice any network issue ?
I think I found,
I did not configure the role HA in the cluster ….
As soon as I can I retest that but suddenly I had my answer, yes normally VM automatically switch. It’s me who missed something
Sorry if this as been already addressed. If we setup a 2 node setup now, and in say 2 years we’ve outgrown the resources, and need to expand. Is there an easy path to add another node to the cluster or are we stuck with tearing it down, and rebuilding with the 3rd node from the start?
Hello,
If you need to expand the cluster, first you need to buy 2x switches. Then you can interconnect all nodes to these switches and add nodes to the cluster. Unfortunately, the created volumes will be stucked in 2-Way Mirroring and you have to delete them to create a 3-Way Mirroring volume or other kind of resiliency.
Hi Romain,
I have implemented your guide successfully, very concise, thank you. i have one problem which I cannot resolve, regarding the SW-1G switch embedded team. Each of the physical adapters are attached to different physical switches, when I power down a switch, the affected port shows “network cable unplugged” in the management OS, but when the switch powers back on, it remains unplugged. If I disable and re-enable the network adapter in the management OS, the connection then shows connected.
i have tried searching the web for this with no luck, any advise would be appreciate. many thanks. Dan OC
Hey,
Did you try to check that with PowerShell (Get-NetAdapter)? Because I don’t trust the GUI :p. The other test you can try is to unplug the other network adapter once you have plugged again the first one. If you can access the server, it’s good 🙂
If it doesn’t work, it’s hardware related.
Hi Romain,
Thank you very much for this interesting article.
I start to ask mysefl to update 2 of my Host and built this kind
I am asking why you didn’t user ConnectX-4 Lx who is a the same price and use the RoCE protocol?
Regards,
Victor
Hey,
I took Connectx3-pro because they were less expensive on Ebay than ConnectX4 LX 🙂 (When I built the servers).
Dear Romain,
merci beaucoup for this excellent article !
I am not an experienced admin so please forgive that some of my questions might be of low quality…
Currently we have a cluster running on basis of KVM (Linux) which is running reliable but quite poor in performance. Having 2 new DL380 Gen10 with XEON 4110 available I thought to give your approach a try. I have installed Datacenter Server 2019 on both nodes, so far everything running fine.
1. One of my NICs refused to set Jumbo Frames 9014 (“value must be between 1500 and 9000”). Is this a problem ? Shall I set it to 9000 in all NICs?
2. Above you test your network with “ping 10.10.0.1 -l 9014”. Which adapter has received this IP in your approach ?
3. You set DNS-Server to 10.10.0.20. Which server is this ? Would it be ok to set it to 127.0.0.0 as the DC runs on this machine and thus the DNS does as well, or not ?
4. Is there any steps that you would do differently in a 2019 installation ?
5. At which point of the installation process the Nested Mirror-Accelerated Parity should be installed ?
6. Which modifications does Nested Mirror-Accelerated Parity require regarding available hardware (HD spaces, cache spaces, etc.) ?
7. Do I understand correctly that both nodes are configured exactly the same, including all IPs etc. ?
Thanks a lot,
Stefan
Hey,
1. Some NICs don’t accept MTU 9014. It’s not an issue. You can configure 9000.
2. I try a ping from my management interface. But you have to do the same for each interface
3. No because it’s not supported to install a DC role on Hyper-V server. I deployed a VM to host DC and this VM has the IP 10.10.0.20
4. No
5. When you create volume (New-Volume)
6. Nested Mirror Accelerated Parity takes more spaces for resiliency. Only 40% is usable. Be careful to get enough SSD/NVMe
7. Both nodes are configured the same excepted name and IP addresses
Hi Romain,
Thanks for your excellent article. I’m not good at network and Windows setting. Your article really help me so much. I already configured a 2 nodes HCI with server 2019 DC with GUI,but i have some confuse about these setting. I bind 2 adapter(1 G for each one) teaming named NIC, create a switch on NIC and create a virtual adapter named VNIC with IP 10.10.0.5&6 and a mellanox 100Gb network adapter named Storage (RDMA enable) with IP 10.10.101.5/6. after create cluster and s2d. When I test VM live migration, on the task manager performance tab, it shows “VNIC” become 600Mbps in short time and “Storage” less than 3Mbps. I think “Storage” work but can’t see, cos when I disable “Storage” and test again, “VNIC” become 300-600Mbps more than 15s. but I don’t know why I can’t see “Storage”‘s real bandwidth and why VNIC became so bigger bandwidth. Do you know how to avoid this cos I want to use VNIC for data between VMs, like SQL data write and read. if the bandwidth was taken by migration affairs, it may affect normal communicate.
Hello,
You should check if you configure Live-Migration on Mellanox adapters (you can see this setting in failover clustering console, right click on Network). If you set Live-Migration with SMB Direct and you enabled RDMA, task manager will show nothing in network adapter. If you want to see RDMA transfer, you have to open Perfmon (RDMA activity)
Awesome Post…thank you. Most all of it I understood… Just a few questions.
I am building my LAB with some retired Data Center equipment here is the list of equipment
2/ DL360 G7 with 12 Logical cores each
8 Local Drives with a Smart Array P410i with SAS 8 drives. 4/200GB SSD and 4/900GB10K drives all but two of the SSDs are configured as logical Drives all but 2/SSD as the OS/System drives.
2/ MSA-60 Arrays with 12 Drives each all SAS…. 4/200GB SSD and 8/3TB HDD Attached with a HP H221 HBA
144 GB of Ram
4 onboard NICs 1Gb
1 Chelesio NIC 10Gb with 2 Ports
Network
1 NETGEAR 8-port Gigabit Ethernet Unmanaged Switch, Desktop, 2x10Gb
1 “Affordable” MikroTik 5-Port Desktop Switch, 1 Gigabit Ethernet Port, 4 SFP+ 10Gbps ($119.00) This is a game changer.
The environment already has 2 Domain Controller on the network.
Most everything in your post works for me except the for not setting up SET on the 10Gb network.
Can I ask you for help with that configurations. I do appreciate anything you can do to help. I do have remote access if you want to look…all the servers are ready for configuration…Fresh install of W2016 DCE the driver are loaded and the server have been patched. I have been working with Storage Spaces for 5 years.
Any help would be appreciated.
Doug
Hi Romain,
After looking through more of your articles I found “How to deploy a converged network with Windows Server 2016”, which is more what I was looking for…thanks for all your content
Hello Roman,
very good article as well as the comments.
a small question, what is the benefit of putting a vlanid on the network cards storage? direct-attach both nodes, do not isolate the traffic already?
Set-NetAdapter -Name Storage-101 -VlanID 101 -Confirm:$False
Set-NetAdapter -Name Storage-102 -VlanID 102 -Confirm:$False
Thanks in advance
Regards
I used to isolate storage networks in VLAN because I do also that in 3 or more node cluster. But yes, if they are isolated physically, it’s not mandatory.
Thank you for the answer.
I have a 2nd question, I tried to set up a hyper-v replica between a cluster hyper-v 2016 with san and a cluster S2D hyper-v 2019 (by following your tutorial)
I created the 2 broker replica (http)
the vm replica between 2019 to 2016, it’s ok.
but it does not work between 2016 and 2019. (it’s ok only 1 time at the beginning)
The vm is well created between the manager of the cluster 2019, but no initial replication ‘error hyper-v-vmms 33680,32354,32004.
if i decide to export the initial replication and re-import it, I have the following errors: 33680,32086,32370.
if anyone has an idea because I do not see.
thanks.
regards
I answer myself, a priori a bug known cluster 2019 server
https://social.technet.microsoft.com/Forums/Lync/en-US/ecd99229-b9fe-45c7-b35e-207c4903f73a/hyperv-cluster-replica-broker-error-quotobject-could-not-be-foundquot-from?forum=winserverhyperv
Glad you found your answer :p
Dear Romain,
my Test-Cluster command fails during the network tests as my direct-connected Mellanox DirectX-5 for Storage-101 and Storage-102 are not reachable. In fact I cannot ping the other node on both networks. All networks running over the switch are working fine… Everything is checked several times, do you have a hint where to look ?
Thanks a lot !
Hello,
Are you sure you have well identified network adapters ? Have you tried to switch between both physical network adapters the cable (on one server) ?
Good morning !
The switching of the cables did the job – thank you so much !!
I have no idea why this should have been the reason but I do not ask any further.. 😉
On all adapters I have set :
IPv4 on (see above settings), IPv6 off
Following are ON : Client for MS networks, QoS Packet Scheduler, MS LLDP driver, Link-layer topology discovery responder, Link-layer topology discovery i/o mapper driver
Is this the correct practice or can I disable something ?
Cheers,
Stefan
Hello,
I always leave the default network settings. So I leave IPv6 off. In general, you should leave IPv6 enabled, it’s a best practice.
Romain, since Windows server 2019 is the new go to platform I wanted to get input on a of the shelf setup using (2) HP DL360 G10 with 4 built in 1 GB nics and an additional HPE FlexFabric 10Gb 2 port 533FLR-T adapter – crossed over into the second server to possibly safe the expense of a pricy 10 GB switch. First 2 drives sata ssds in hw raid 1 for the OS – next 2 drives sas ssds (2×1.9 TB) in hw raid one as cache – next 4 drives (4X 2.4 TB SAS hw raid 5 main storage)
This is supposed to become a small cluster to hold a couple of vms in a DMZ. I would like to create this outside /without domain context as this should be possible now. Any insights/thoughts greatly welcome.
Hello,
You can’t deploy S2D without a domain because S2D is based on SMB3. Authentication against Active Directory is mandatory for storage and live migration.
Moreover it is not supported to set RAID and S2D on top. You must install passthrough HBA and it’s Windows Server that handle resiliency.
Thank you Romain much appreciated.
Dear Romain,
I am running the cluster as per your description for several weeks now. Now, out of nowhere, the cluster heartbeat network is not working anymore. On both nodes, the heartbeat is just sending and not receiving.
I have checked again IP and VLAN settings, disabled and re-enabled the networks etc but the situation remains unchanged.
The Management Network running on the same Virtual Switch is working fine.
Do you have an idea what to check ?
Thanks a lot,
Stefan
Hello Stefan,
If you have a management networ and two storage networks, yo ucan delete the heartbeat network (remove virtual net adapter). Management and Storage network adapters are enough to handle the heartbeat. I should update this topic and remove the heartbeat network adapters.
Hi Romain,
I’ve been running this configuration in production for 2 years, 2 node with no issues until now and i’m really hoping you can help.
The cluster has gone offline and I cannot ping it, i’ve called in Microsoft on a business critical case, but they seem to believe that the Cluster won’t come online until the network issue is sorted. My cluster IP for Cluster-Hyv01 is 192.168.16.15, but wont respond to any pings. I had presumed it won’t ping as the cluster is offline. Is this right? Or would it ping even if it was online.
Luckily the VMs are all running still, but I obviously need to get to the bottom of the problem, any help or advice would be appreciated.
Hello,
Your cluster networks are up ?
Networks are up but the cluster says offline. Cluster group is reporting pending.
if i have only two NIC can i do the hyper converged?
Yes if you have switches in your infrastructure.
Hello! This is the article I was really looking for. While looking for a solution for HA, I found out that S2D makes it possible without storage. I have refer to many guides, but the most curious is the quorum configuration.
Normal MSCS configures quorum on storage, but S2D “A Disk witness isn’t supported with Storage Spaces Direct” The other way is file share witness or Azure colud witness, but where there is no internet connection.
In this situation, “SMB file share that is configured on a file server running Windows Server” is this phrase to connect a network drive from a seperate server and use it as a quorum?
I also found these documents,
What’s new in storage in Windows Server 2019 and Windows Server, version 1809
Two-server clusters using a USB flash drive as a witness
Use a low-cost USB flash drive plugged into your router to act as a witness in two-server clusters. If a server goes down and then back up, the USB drive cluster knows which server has the most up-to-date data. For more info, see the Storage at Microsoft blog.
Please advise if you know how this is possible.
Hello Brad,
would you mind to share the links to these articles ?
Thanks,
Stefan
Hi,
Maybe here for example 🙂 :
https://charbelnemnom.com/2018/08/how-to-configure-file-share-witness-with-usb-thumb-drive-on-windowsserver2019-windowsserver-s2d-cluster-storagespacesdirect/
or here:
https://techcommunity.microsoft.com/t5/failover-clustering/new-file-share-witness-feature-in-windows-server-2019/ba-p/372149
Bonjour Romain. Thank you so much for this article. It helped me immensely.
I have 2 x nodes with 24 cores (48 hyper-threading). How would you setup “Set-NetAdapterRSS” differently?
New-NetIPAddress -InterfaceAlias “vEthernet (Management-0)” -IPAddress 10.10.0.5 -PrefixLength 24 -DefaultGateway 10.10.0.1 -Type Unicast | Out-Null
Set-DnsClientServerAddress -InterfaceAlias “vEthernet (Management-0)” -ServerAddresses 10.10.0.20 | Out-Null
New-NetIPAddress -InterfaceAlias “vEthernet (Cluster-100)” -IPAddress 10.10.100.5 -PrefixLength 24 -Type Unicast | Out-Null
New-NetIPAddress -InterfaceAlias “Storage-101” -IPAddress 10.10.101.5 -PrefixLength 24 -Type Unicast | Out-Null
New-NetIPAddress -InterfaceAlias “Storage-102” -IPAddress 10.10.102.5 -PrefixLength 24 -Type Unicast | Out-Null
#Disable DNS registration of Storage and Cluster network adapter (Thanks to Philip Elder :))
Set-DNSClient -InterfaceAlias Storage* -RegisterThisConnectionsAddress $False
Set-DNSClient -InterfaceAlias *Cluster* -RegisterThisConnectionsAddress $False
This IP configuration was very confusing.
Should I run these commands on both nodes?
Yes commands on both nodes however change the IP addressing respectively.
Node 1 has above IP addresses.
Node 2 just needs all IP addresses in same subnets but one-up on each number.
For example Node 2’s “Cluster-100” IP details can be:
New-NetIPAddress -InterfaceAlias “vEthernet (Cluster-100)” -IPAddress 10.10.100.6 -PrefixLength 24 -Type Unicast | Out-Null
Hello I have the following errors in the Test-Cluster report :
Network interfaces MPWS2D01.smag.local – vEthernet (Cluster) and MPWS2D02.smag.local – vEthernet (Cluster) are on the same cluster network, yet address 172.16.4.31 is not reachable from 172.16.4.30 using UDP on port 3343.
Network interfaces MPWS2D02.smag.local – vEthernet (Cluster) and MPWS2D01.smag.local – vEthernet (Cluster) are on the same cluster network, yet address 172.16.4.30 is not reachable from 172.16.4.31 using UDP on port 3343.
Could you please help me ?
Thanks
What subnet mask are you using for each vEthernet?
And the obvious question… is the port and protocol open on the firewall? Even if it only allows access from the same subnet.
Great video, congrats! Quick question. What will happen if one node fails? I do not mean shutdown/restart but total fail like power, for example, or NIC issue. The VMs running on the affected node will be transferred to the new right, but in what state? What about VMs with large amount of RAM?
Dear Romain,
I have made a complete new setup after my old one went into strange and not really understandable problems. For this setup I have put my DC out of the cluster as I feel more comfortable with this..
However, during the new setup with Server 2019 I am running into two issues :
1. Test-Cluster is not working as it says that test “Network” was not found in the list of loaded tests.
2. However, I can run the test with the Failovercluster-Manager. It runs into a Network warning saying that DHCP status of vEthernet(Management-0) is differing from network “Cluster Network 3”. Of course I have given vEthernet(Management-0) a fix address.
The strange thing is that “Cluster Network 3” at that moment does not exist yet…
Any idea ?
Thanks a lot,
Stefan
Dear Romain, great article. If i lost one node(replace), how i rebuild the node?
Hi Jean. I have feeling, you have to recover from an image, or build from scratch…
Hi Romain, thanks so much for this article. I am at building my first 2 node cluster on Windows Server 2019 and looking for a step by step tutorial about the network configuration I found yours. I am not sure about “Set-NetAdapterRSS” because each of my servers runs 2 Xeon CPUs with 8 cores each. How many cores should I assign to each network adapter?
Hi Romain, Great Article! Clusters is a new world for me, so I’m probably going to ask obvious questions.
I’ve two servers with Hyper-V Server 2019 and many VM’s on each. DC’s are 2 VM’s, 1 in each server so i have a sort of HA using 2 dns, dhcps, dfs-namespace and replica. and so on…they work fine. Obviously some applications and service don’t have HA.
I’d like to adopt a new configuration using Failover Clustering using storage space direct because a can’t buy a san or something similar. So you article is a great guide for me.
There are some aspect i can’t understand…
I was thinkng to make a cluster with 2 server with Hyper-V Server 2019 on (not windows server ), is it possible?
You suggest to put dc outside cluster as a phisical server, but it could be a point of failure.. so i have more physical server for dc, COrrect?
Why don’t you put DCs into the cluster? i’ve read that the cluster boot also there isn’t an active domain controller from WS2016. I think the answer is about the time DC take to boot on the alive node when the other node fail…and if i have more than 1 dc into the cluster nothing change… dcs native ha is the best way… is it right?
Last question is about the HD: now, i’ve a lot of SAS 2.5″ 10/15K in raid 5 or 50 configuration plus other 3.5 sas storage. You say storage direct work only in jbod mode (not raid) and if i have raid controller they are useless and degrade performance.. How can i save my money using my hd and controller?
Really, your solutions should be great for me but your is a test lab and use Hyper-v to virtualize the 2 DCs and the cluster itself but could this solution have sense in a production enviroment?
Thank you so much… i’m sorry but i’m not an it manager
DevOps is a new trend in software development over the past few years. Although the term is relatively new, it is actually a combination of many practices that have been in use for years. DevOps allows software to be released quickly and efficiently, while still maintaining high levels of security. for more visit Azure devops backup